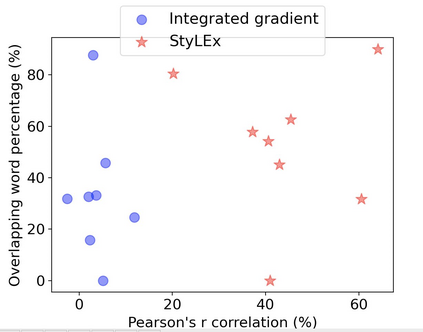
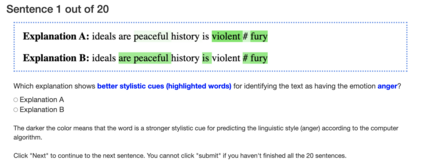
Large pre-trained language models have achieved impressive results on various style classification tasks, but they often learn spurious domain-specific words to make predictions (Hayati et al., 2021). While human explanation highlights stylistic tokens as important features for this task, we observe that model explanations often do not align with them. To tackle this issue, we introduce StyLEx, a model that learns from human-annotated explanations of stylistic features and jointly learns to perform the task and predict these features as model explanations. Our experiments show that StyLEx can provide human-like stylistic lexical explanations without sacrificing the performance of sentence-level style prediction on both in-domain and out-of-domain datasets. Explanations from StyLEx show significant improvements in explanation metrics (sufficiency, plausibility) and when evaluated with human annotations. They are also more understandable by human judges compared to the widely-used saliency-based explanation baseline.
翻译:大型预训练语言模型在各种样式分类任务上取得了令人印象深刻的结果,但它们经常学习到虚假的领域特定词汇以进行预测 (Hayati等,2021)。虽然人类解释强调样式标记作为此任务的重要特征,但我们观察到模型解释通常与之不一致。为了解决这个问题,我们引入了 StyLEx,这是一个模型,它从人工注释的样式特征解释中学习,并共同学习执行任务和预测这些特征作为模型解释。我们的实验表明,StyLEx 可以提供类似于人类的风格词汇解释,而不会牺牲句子级风格预测的性能,同时应用于领域内和领域外的数据集。与广泛使用的基于显著性的解释基准相比,StyLEx 的解释显示了解释度量 (充分性、可信度) 的显着提高。在人类注释方面,它们也比基线有更高的可理解性。