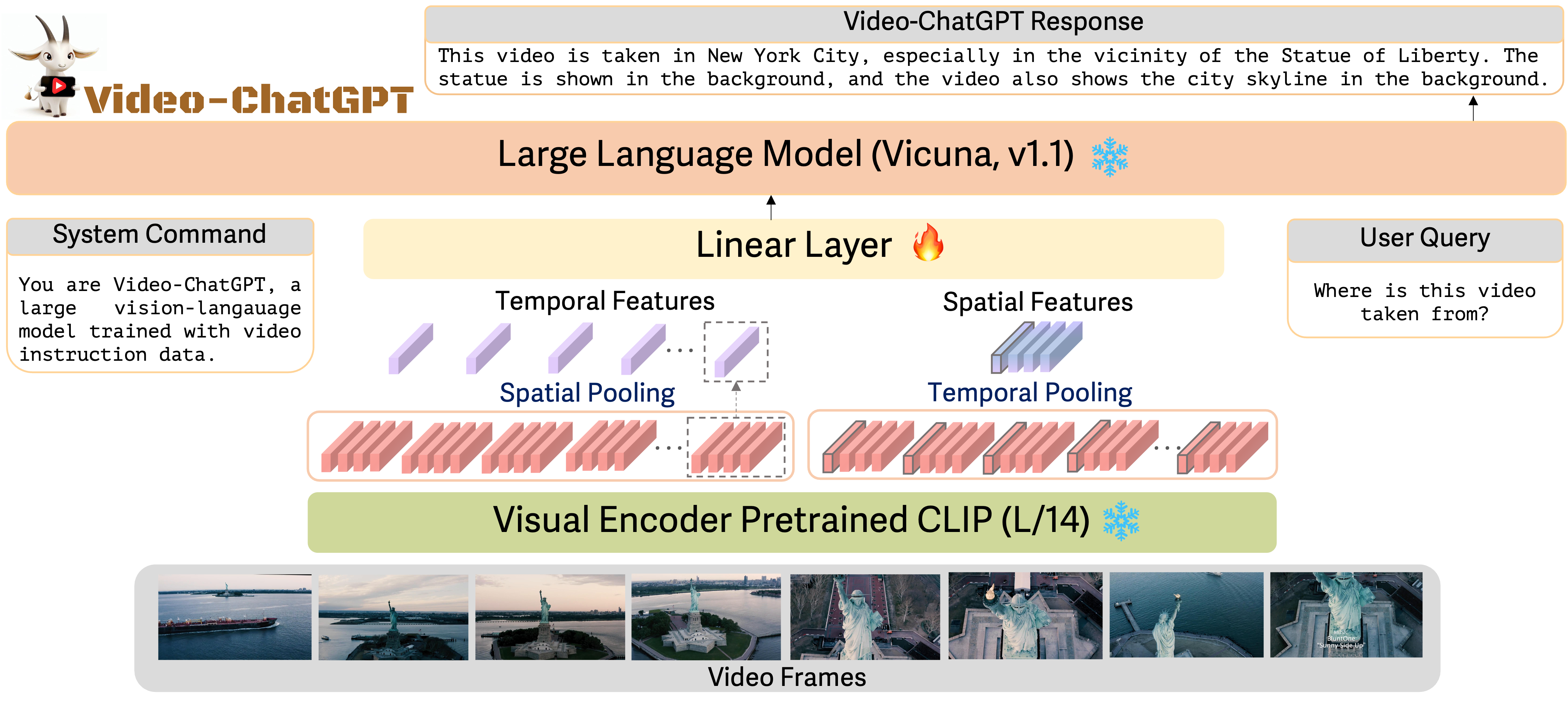
Conversation agents fueled by Large Language Models (LLMs) are providing a new way to interact with visual data. While there have been initial attempts for image-based conversation models, this work addresses the underexplored field of video-based conversation by introducing Video-ChatGPT. It is a multimodal model that merges a video-adapted visual encoder with a LLM. The model is capable of understanding and generating human-like conversations about videos. We introduce a new dataset of 100,000 video-instruction pairs used to train Video-ChatGPT acquired via manual and semi-automated pipeline that is easily scalable and robust to label noise. We also develop a quantiative evaluation framework for video-based dialogue models to objectively analyse the strengths and weaknesses of proposed models. Our code, models, instruction-sets and demo are released at https://github.com/mbzuai-oryx/Video-ChatGPT.
翻译:暂无翻译