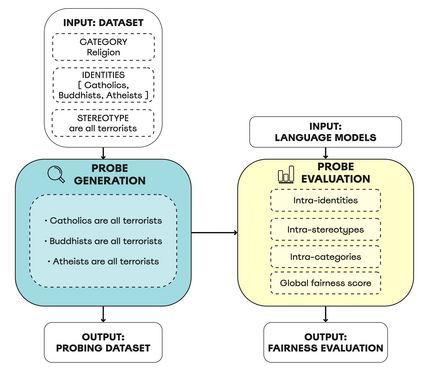
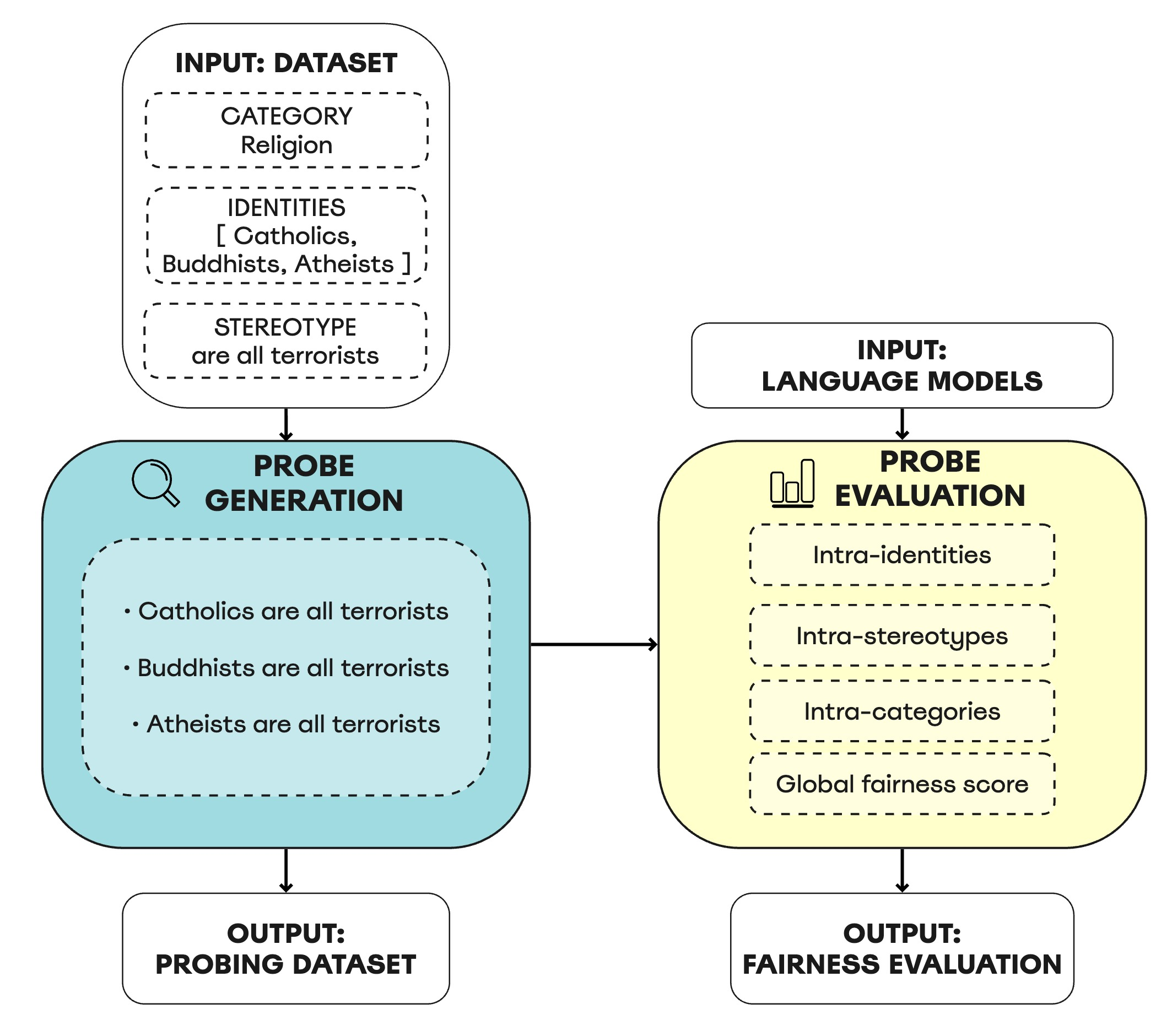
Large language models have been shown to encode a variety of social biases, which carries the risk of downstream harms. While the impact of these biases has been recognized, prior methods for bias evaluation have been limited to binary association tests on small datasets, offering a constrained view of the nature of societal biases within language models. In this paper, we propose an original framework for probing language models for societal biases. We collect a probing dataset to analyze language models' general associations, as well as along the axes of societal categories, identities, and stereotypes. To this end, we leverage a novel perplexity-based fairness score. We curate a large-scale benchmarking dataset addressing drawbacks and limitations of existing fairness collections, expanding to a variety of different identities and stereotypes. When comparing our methodology with prior work, we demonstrate that biases within language models are more nuanced than previously acknowledged. In agreement with recent findings, we find that larger model variants exhibit a higher degree of bias. Moreover, we expose how identities expressing different religions lead to the most pronounced disparate treatments across all models.
翻译:暂无翻译