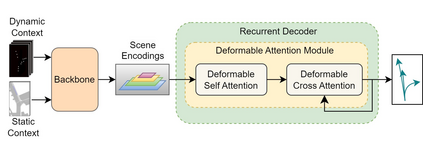
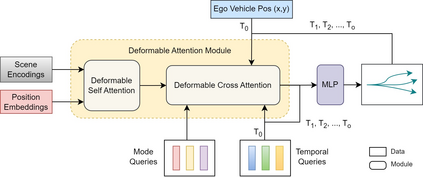
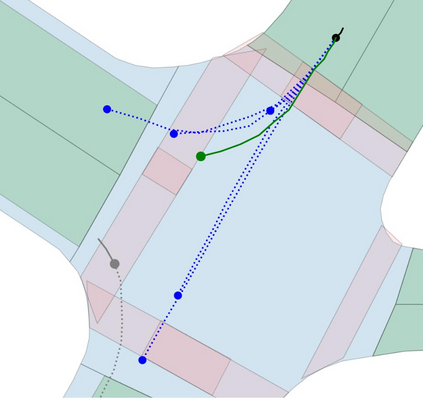
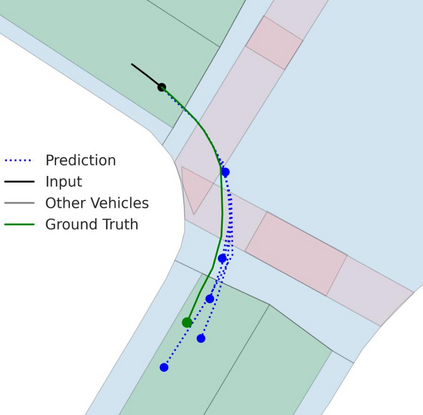
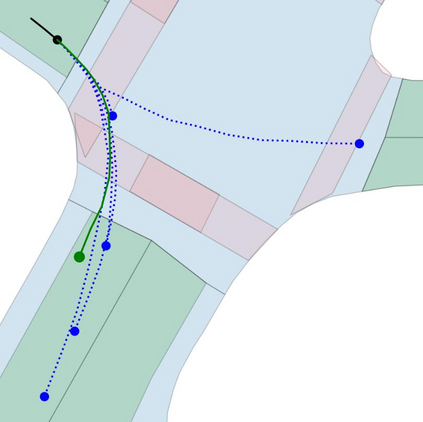
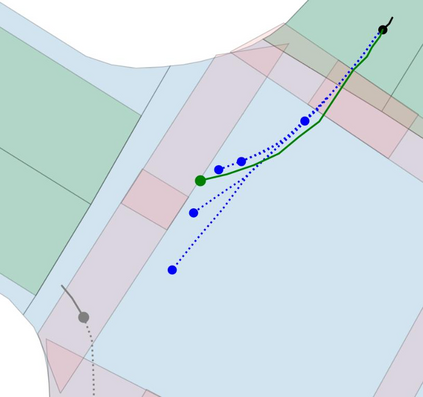
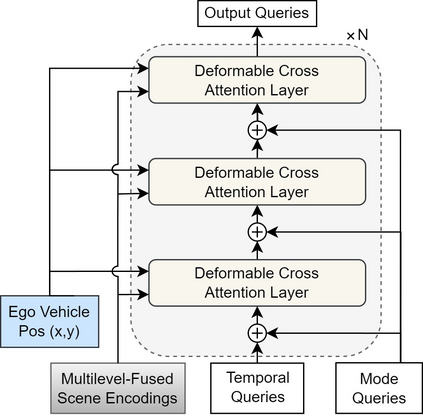
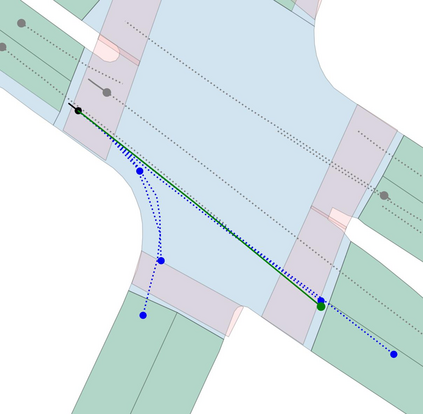
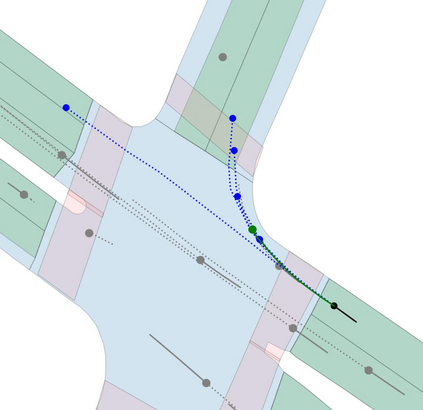
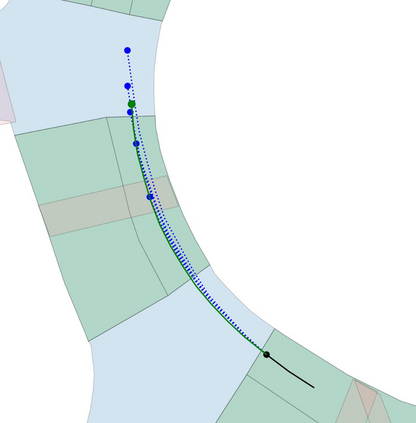
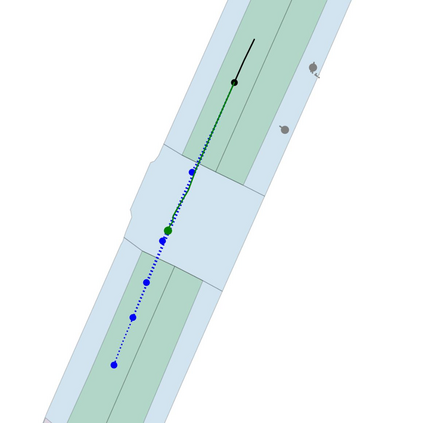
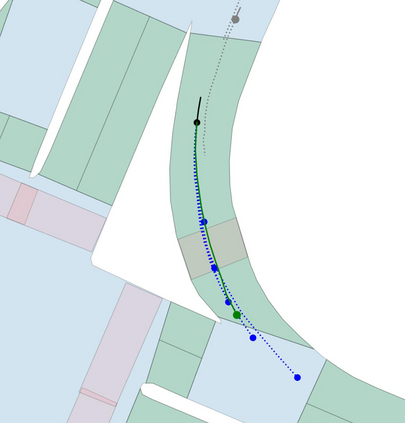
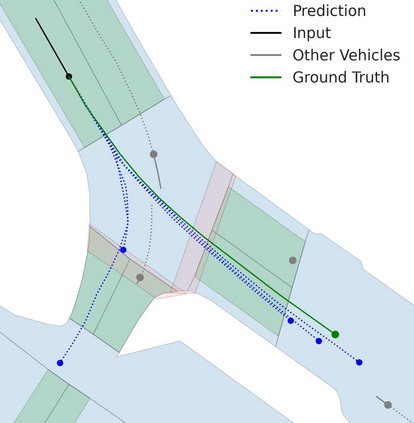
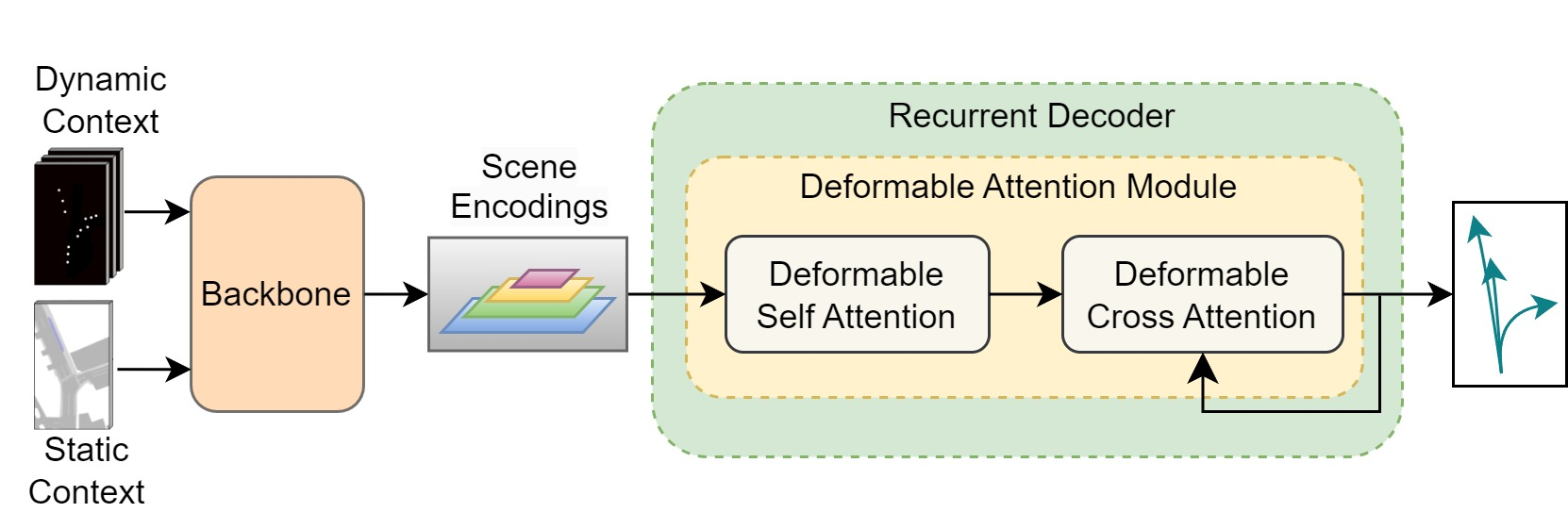
Motion prediction is an important aspect for Autonomous Driving (AD) and Advance Driver Assistance Systems (ADAS). Current state-of-the-art motion prediction methods rely on High Definition (HD) maps for capturing the surrounding context of the ego vehicle. Such systems lack scalability in real-world deployment as HD maps are expensive to produce and update in real-time. To overcome this issue, we propose Context Aware Scene Prediction Transformer (CASPFormer), which can perform multi-modal motion prediction from rasterized Bird-Eye-View (BEV) images. Our system can be integrated with any upstream perception module that is capable of generating BEV images. Moreover, CASPFormer directly decodes vectorized trajectories without any postprocessing. Trajectories are decoded recurrently using deformable attention, as it is computationally efficient and provides the network with the ability to focus its attention on the important spatial locations of the BEV images. In addition, we also address the issue of mode collapse for generating multiple scene-consistent trajectories by incorporating learnable mode queries. We evaluate our model on the nuScenes dataset and show that it reaches state-of-the-art across multiple metrics
翻译:暂无翻译