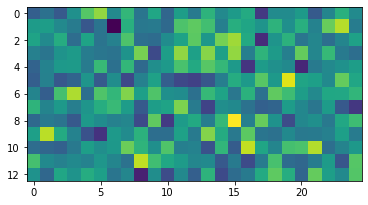
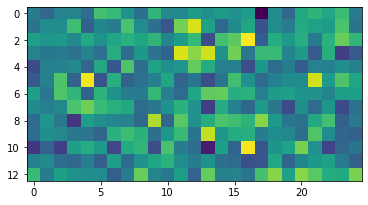
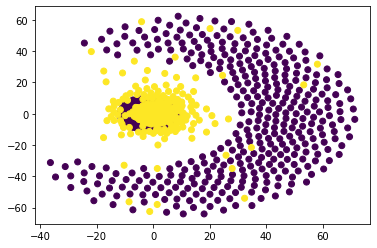
This work investigates and evaluates multiple defense strategies against property inference attacks (PIAs), a privacy attack against machine learning models. Given a trained machine learning model, PIAs aim to extract statistical properties of its underlying training data, e.g., reveal the ratio of men and women in a medical training data set. While for other privacy attacks like membership inference, a lot of research on defense mechanisms has been published, this is the first work focusing on defending against PIAs. With the primary goal of developing a generic mitigation strategy against white-box PIAs, we propose the novel approach property unlearning. Extensive experiments with property unlearning show that while it is very effective when defending target models against specific adversaries, property unlearning is not able to generalize, i.e., protect against a whole class of PIAs. To investigate the reasons behind this limitation, we present the results of experiments with the explainable AI tool LIME. They show how state-of-the-art property inference adversaries with the same objective focus on different parts of the target model. We further elaborate on this with a follow-up experiment, in which we use the visualization technique t-SNE to exhibit how severely statistical training data properties are manifested in machine learning models. Based on this, we develop the conjecture that post-training techniques like property unlearning might not suffice to provide the desirable generic protection against PIAs. As an alternative, we investigate the effects of simpler training data preprocessing methods like adding Gaussian noise to images of a training data set on the success rate of PIAs. We conclude with a discussion of the different defense approaches, summarize the lessons learned and provide directions for future work.
翻译:这项工作调查并评估了针对财产推断攻击(PIAs)的多重防御战略,这是针对机器学习模式的一种隐私攻击。在经过培训的机器学习模式下,PIAs旨在提取其基本培训数据统计属性的统计属性,例如,在医疗培训数据集中披露男女比例。对于其他隐私攻击,例如会员推断,已经公布了许多关于国防机制的实验结果,这是针对财产推断攻击(PIAs)的首项工作。我们提出针对白盒 PIAs的隐私攻击(PIAs)的隐私攻击(PiAs)的首要目标是制定一般性缓解战略。我们建议采用新颖的不学习方法。在不学习财产的大规模实验中,在保护目标模型的目标模型中保护目标模型非常有效,在保护目标模型的目标模型中,不进行较简化的排序后,我们使用数据分析后的方法来进行数据分析。我们使用模型的模拟数据学习方法,我们用模型来分析模型的正确分析。