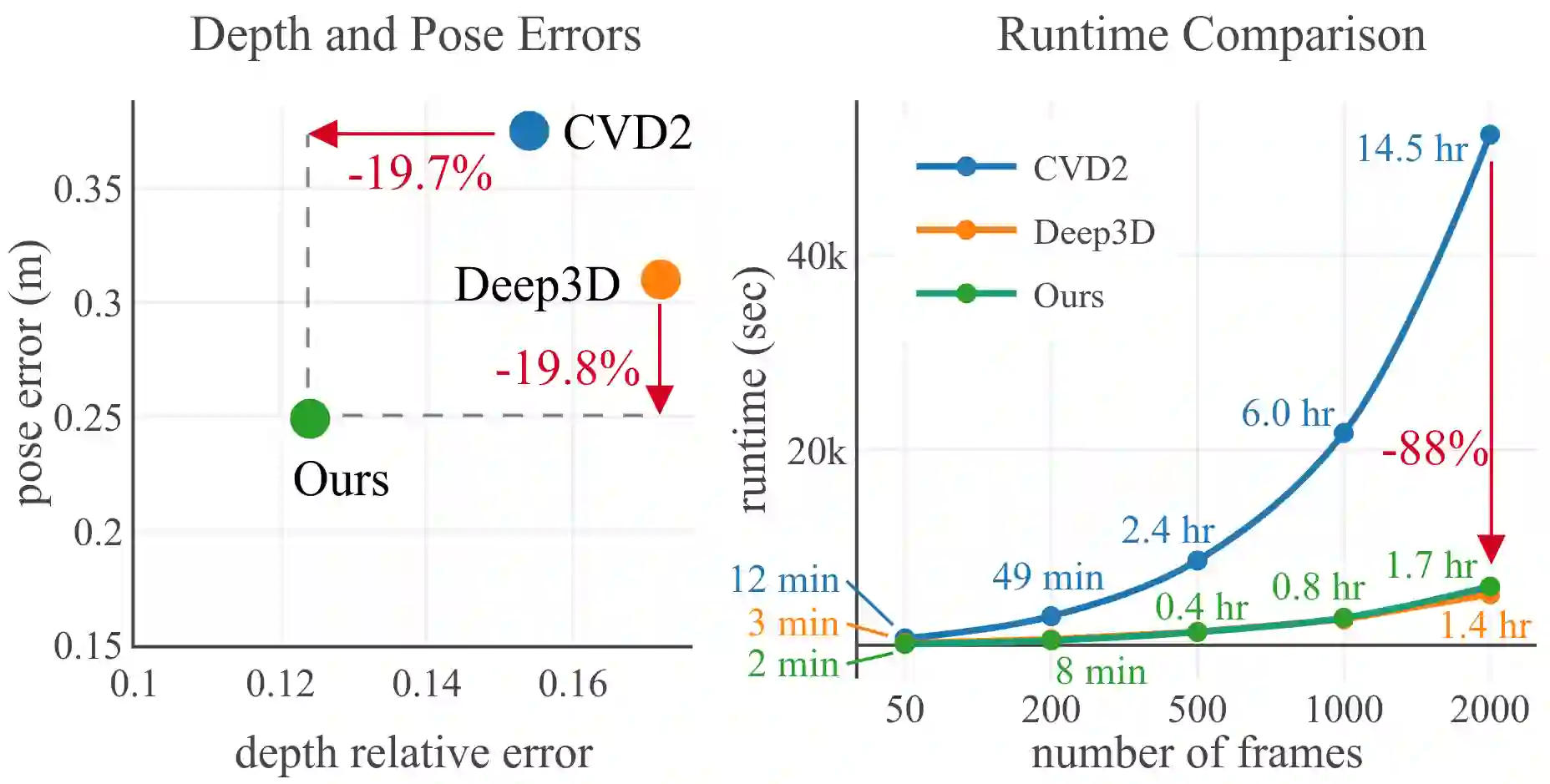
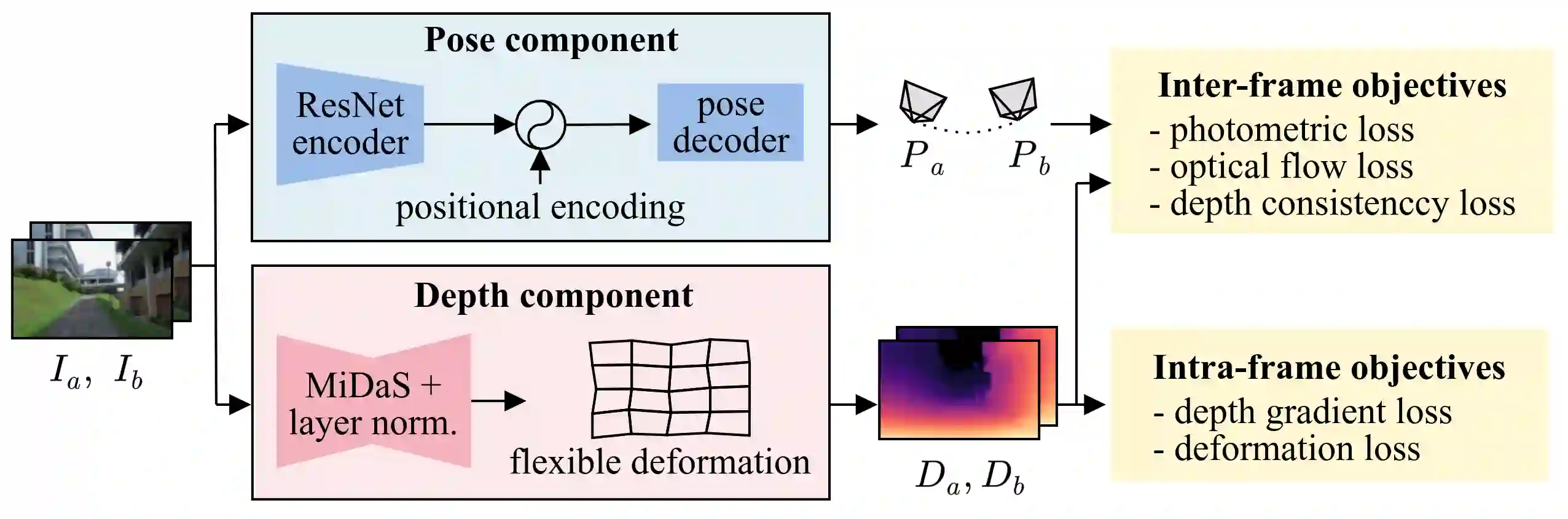
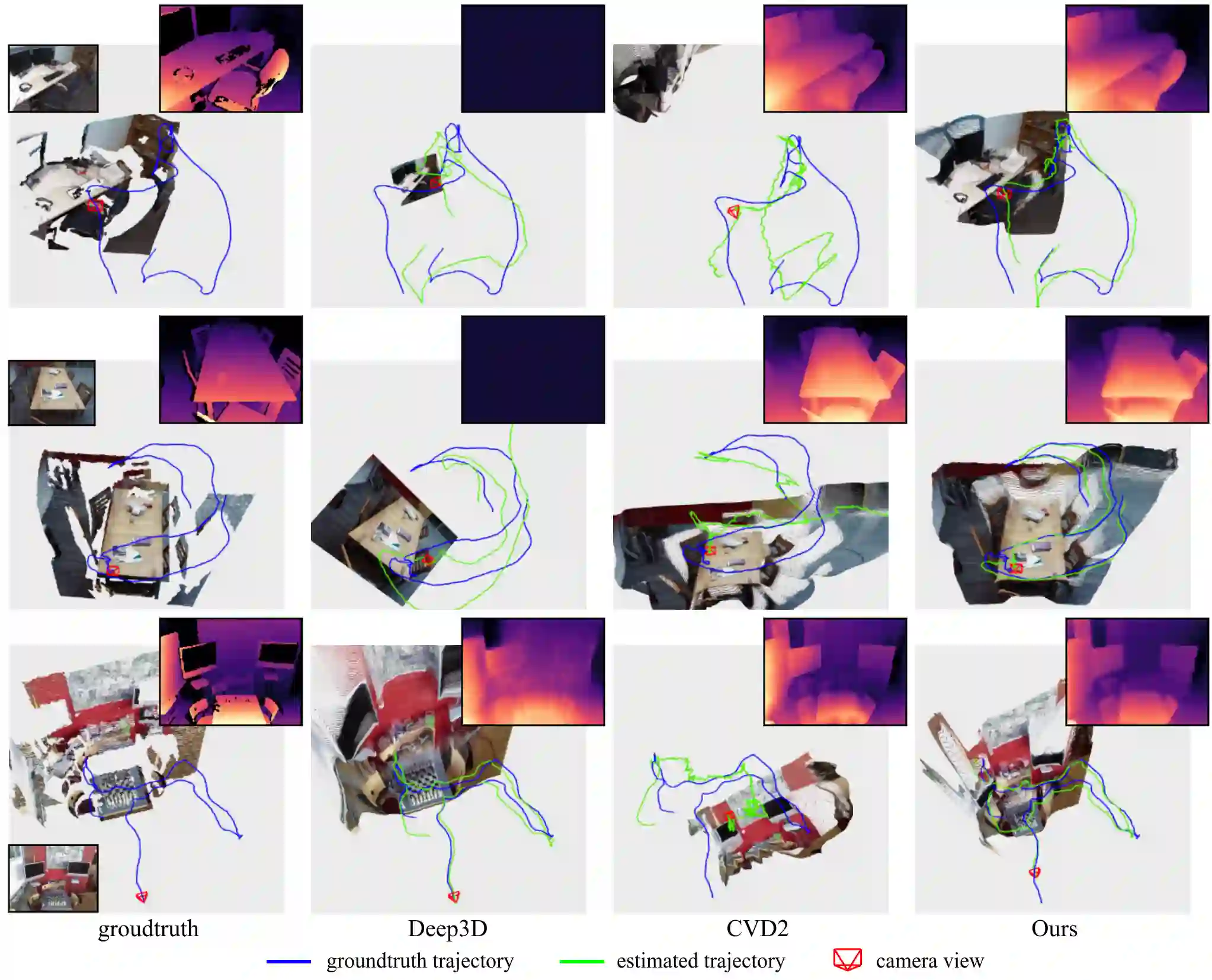
Dense depth and pose estimation is a vital prerequisite for various video applications. Traditional solutions suffer from the robustness of sparse feature tracking and insufficient camera baselines in videos. Therefore, recent methods utilize learning-based optical flow and depth prior to estimate dense depth. However, previous works require heavy computation time or yield sub-optimal depth results. We present GCVD, a globally consistent method for learning-based video structure from motion (SfM) in this paper. GCVD integrates a compact pose graph into the CNN-based optimization to achieve globally consistent estimation from an effective keyframe selection mechanism. It can improve the robustness of learning-based methods with flow-guided keyframes and well-established depth prior. Experimental results show that GCVD outperforms the state-of-the-art methods on both depth and pose estimation. Besides, the runtime experiments reveal that it provides strong efficiency in both short- and long-term videos with global consistency provided.
翻译:传统的解决方案因零星地物跟踪和视频摄像基线不足而受到影响。因此,最近的方法在估计密度之前使用基于学习的光学流和深度,然而,以往的工作需要大量计算时间或产生低于最佳深度的结果。我们从本文的动作(SfM)中提出全球一致的基于学习的视频结构方法GCVD。GCVD在有线电视新闻网基础上的优化中加入了一个压缩的图像图,以便从有效的关键框架选择机制中实现全球一致的估算。它可以改进以学习为基础的方法的稳健性,同时使用流动制导关键框架,并事先建立完善的深度。实验结果显示,GCVD在深度和表面估计上都优于最先进的方法。此外,运行时间实验显示,它提供了全球一致性的短期和长期视频的强大效率。