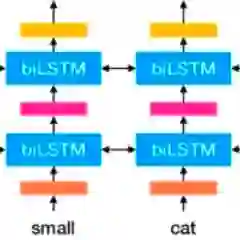
The first two tasks of the CLEF 2019 ProtestNews events focused on distinguishing between protest and non-protest related news articles and sentences in a binary classification task. Among the submissions, two well performing models have been chosen in order to replace the existing word embeddings word2vec and FastTest with ELMo and DistilBERT. Unlike bag of words or earlier vector approaches, ELMo and DistilBERT represent words as a sequence of vectors by capturing the meaning based on contextual information in the text. Without changing the architecture of the original models other than the word embeddings, the implementation of DistilBERT improved the performance measured on the F1-Score of 0.66 compared to the FastText implementation. DistilBERT also outperformed ELMo in both tasks and models. Cleaning the datasets by removing stopwords and lemmatizing the words has been shown to make the models more generalizable across different contexts when training on a dataset with Indian news articles and evaluating the models on a dataset with news articles from China.
翻译:CLEF 2019 抗议新闻头两项任务侧重于区分抗议和非抗议相关新闻文章和二进制分类任务中的句子。 在提交材料中,选择了两种表现良好的模式,以替换现有的单词嵌入字2vec和快速测试, 以 ELMO 和 DistilBERT 取代现有的单词嵌入字2vec 和 ELMO 和 FastillBERT 。 不同于一袋单词或更早的矢量方法, ELMO 和 DiptillBERT 将单词作为矢量序列, 获取文本中基于背景信息的含义 。 在不改变原模型结构而非单词嵌入结构的情况下, DistillBERT 的实施提高了F1- Score 0.66 的性能, 与 F1- Scream 相比, FastText 执行的性能。 DitillBERT 在任务和模型中, DustillBERT 也都超过了 ELM 。 在删除断字和文字时, 已经展示了数据集, 使模型在不同的环境中更加普及, 在不同的场合中可以使模型在不同的场合中更加普及。 当关于印度新闻文章的数据集培训时, 时, 。