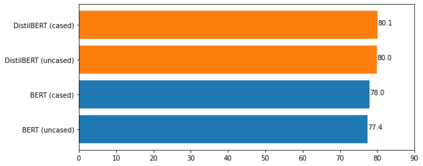
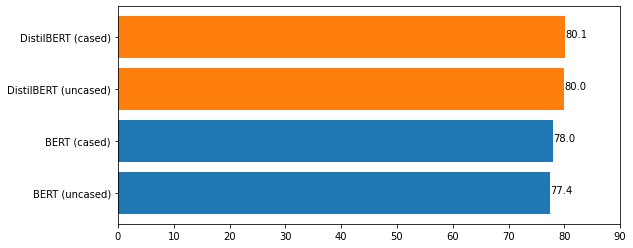
Formality is an important characteristic of text documents. The automatic detection of the formality level of a text is potentially beneficial for various natural language processing tasks, such as retrieval of texts with a desired formality level, integration in language learning and document editing platforms, or evaluating the desired conversation tone by chatbots. Recently two large-scale datasets were introduced for multiple languages featuring formality annotation. However, they were primarily used for the training of style transfer models. However, detection text formality on its own may also be a useful application. This work proposes the first systematic study of formality detection methods based on current (and more classic) machine learning methods and delivers the best-performing models for public usage. We conducted three types of experiments -- monolingual, multilingual, and cross-lingual. The study shows the overcome of BiLSTM-based models over transformer-based ones for the formality classification task. We release formality detection models for several languages yielding state of the art results and possessing tested cross-lingual capabilities.
翻译:自动检测文本的正规程度对于各种自然语言处理任务可能是有益的,例如检索具有理想的正规程度的文本,融入语言学习和文件编辑平台,或评价聊天室想要的谈话语调。最近为具有正规性注释的多种语言引入了两个大型数据集。然而,这些数据主要用于培训风格传输模式。但是,检测文本的正规程度本身也可能是一种有用的应用。这项工作提议根据当前(和较经典)机器学习方法,对正规性检测方法进行首次系统研究,并提供最佳的公共使用模式。我们进行了三类实验 -- -- 单一语言、多语言和跨语言的实验。研究显示克服了基于BILSTM的模型而不是基于变压器的模型来完成正规性分类任务。我们为产生艺术成果并拥有经过测试的跨语言能力的若干语言发布了形式检测模型。