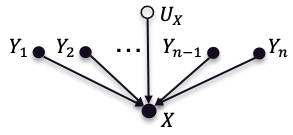
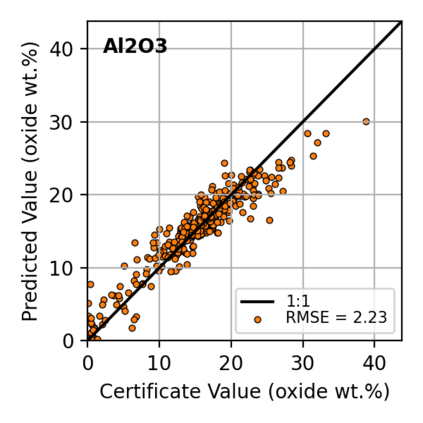
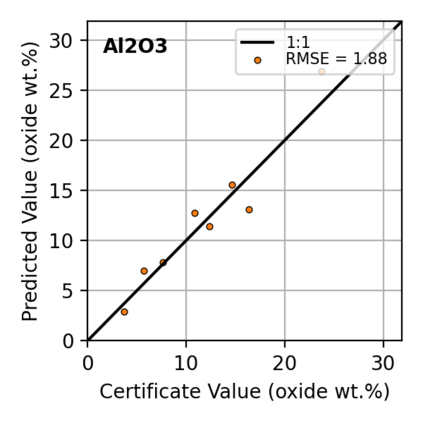
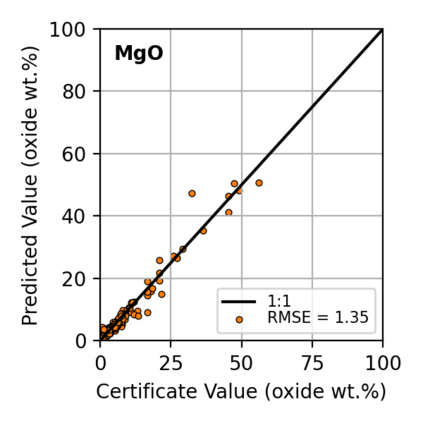
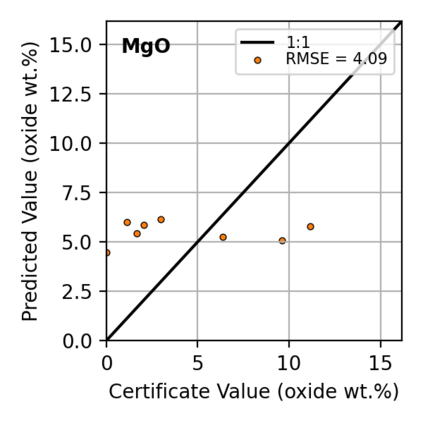
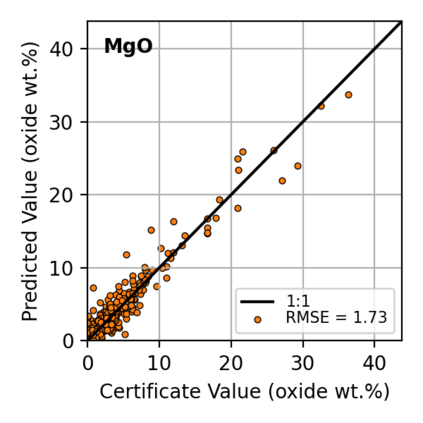
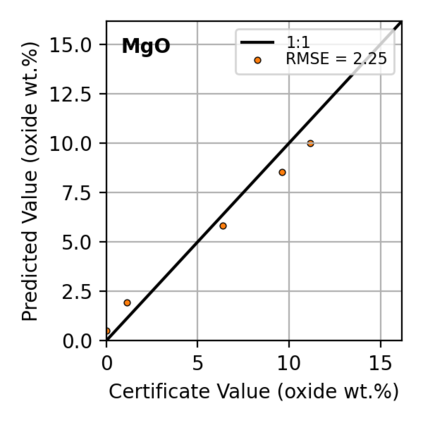
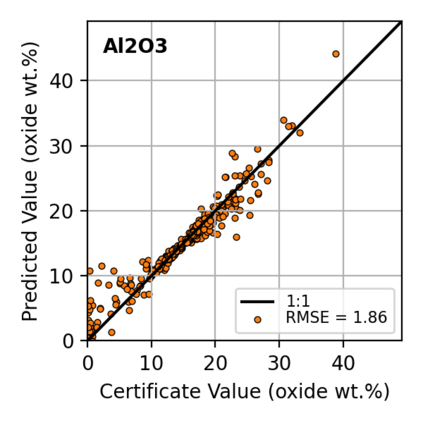
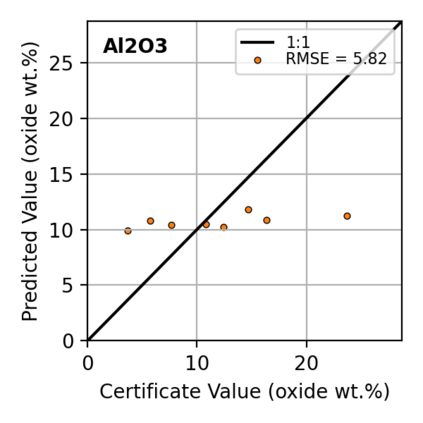
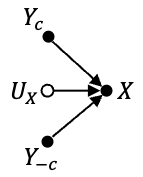
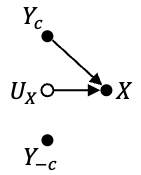
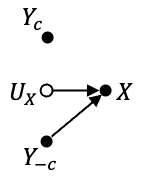
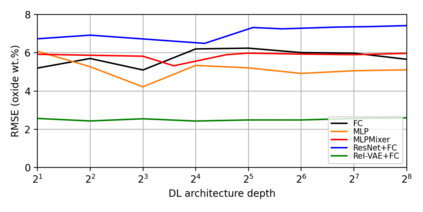
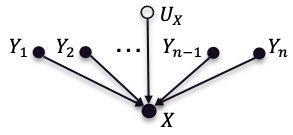
In this work, we propose the use of a causal collider structured model to describe the underlying data generative process assumptions in disentangled representation learning. This extends the conventional i.i.d. factorization assumption model $p(\mathbf{y}) = \prod_{i} p(\mathbf{y}_i )$, inadequate to handle learning from biased datasets (e.g., with sampling selection bias). The collider structure, explains that conditional dependencies between the underlying generating variables may be exist, even when these are in reality unrelated, complicating disentanglement. Under the rubric of causal inference, we show this issue can be reconciled under the condition of causal identification; attainable from data and a combination of constraints, aimed at controlling the dependencies characteristic of the \textit{collider} model. For this, we propose regularization by identification (ReI), a modular regularization engine designed to align the behavior of large scale generative models with the disentanglement constraints imposed by causal identification. Empirical evidence on standard benchmarks demonstrates the superiority of ReI in learning disentangled representations in a variational framework. In a real-world dataset we additionally show that our framework, results in interpretable representations robust to out-of-distribution examples and that align with the true expected effect from domain knowledge.
翻译:暂无翻译