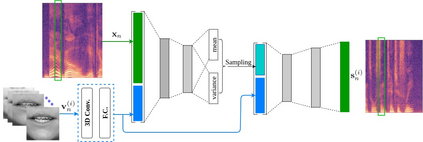
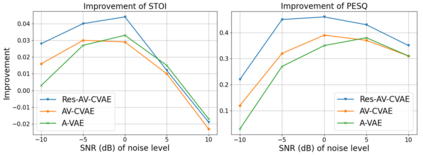
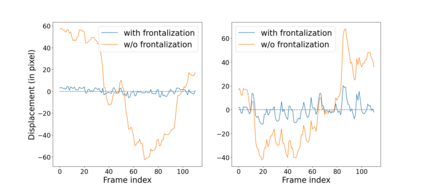
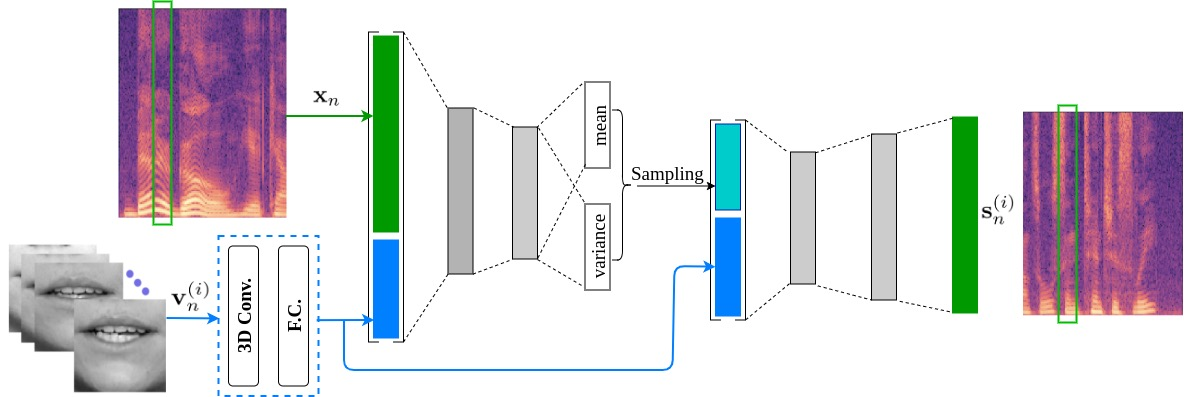
This paper investigates the impact of head movements on audio-visual speech enhancement (AVSE). Although being a common conversational feature, head movements have been ignored by past and recent studies: they challenge today's learning-based methods as they often degrade the performance of models that are trained on clean, frontal, and steady face images. To alleviate this problem, we propose to use robust face frontalization (RFF) in combination with an AVSE method based on a variational auto-encoder (VAE) model. We briefly describe the basic ingredients of the proposed pipeline and we perform experiments with a recently released audio-visual dataset. In the light of these experiments, and based on three standard metrics, namely STOI, PESQ and SI-SDR, we conclude that RFF improves the performance of AVSE by a considerable margin.
翻译:本文调查了头部运动对视听语音增强的影响。虽然头部运动是一个常见的谈话特征,但过去和最近的研究都忽略了头部运动:它们挑战今天的学习方法,因为它们常常降低在清洁、正面和稳定面貌图像方面受过训练的模型的性能。为了缓解这一问题,我们提议使用稳健的面部化(RF)和AVSE方法,同时采用基于变式自动读取器(VAE)模型的AVSE方法。我们简单描述拟议管道的基本成分,并用最近公布的视听数据集进行实验。根据这些实验,我们根据三个标准指标,即STOI、PESQ和SI-SDR,我们得出结论,RFF大大改进了AVSE的性能。