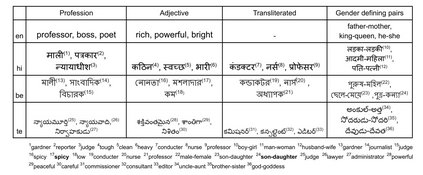
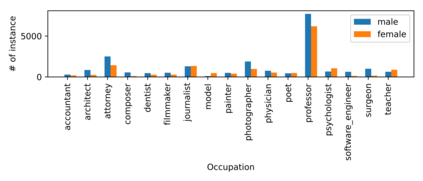
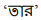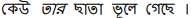In this paper, we advance the current state-of-the-art method for debiasing monolingual word embeddings so as to generalize well in a multilingual setting. We consider different methods to quantify bias and different debiasing approaches for monolingual as well as multilingual settings. We demonstrate the significance of our bias-mitigation approach on downstream NLP applications. Our proposed methods establish the state-of-the-art performance for debiasing multilingual embeddings for three Indian languages - Hindi, Bengali, and Telugu in addition to English. We believe that our work will open up new opportunities in building unbiased downstream NLP applications that are inherently dependent on the quality of the word embeddings used.
翻译:在本文中,我们推广目前最先进的降低单语语言嵌入率的方法,以便在多语种环境中全面推广。我们考虑了用不同方法量化单一语言和多语种环境中的偏见和不同贬入率方法。我们展示了我们对下游NLP应用的减少偏入率方法的重要性。我们提出的方法建立了降低印度三种语言(印地语、孟加拉语和泰鲁古语)多语嵌入率的最先进的表现。我们认为,我们的工作将开辟新的机会,建设无偏见的下游NLP应用,这些应用本身取决于所用语言嵌入的质量。