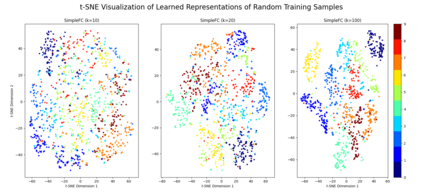
Double descent presents a counter-intuitive aspect within the machine learning domain, and researchers have observed its manifestation in various models and tasks. While some theoretical explanations have been proposed for this phenomenon in specific contexts, an accepted theory to account for its occurrence in deep learning remains yet to be established. In this study, we revisit the phenomenon of double descent and demonstrate that its occurrence is strongly influenced by the presence of noisy data. Through conducting a comprehensive analysis of the feature space of learned representations, we unveil that double descent arises in imperfect models trained with noisy data. We argue that double descent is a consequence of the model first learning the noisy data until interpolation and then adding implicit regularization via over-parameterization acquiring therefore capability to separate the information from the noise. We postulate that double descent should never occur in well-regularized models.
翻译:暂无翻译