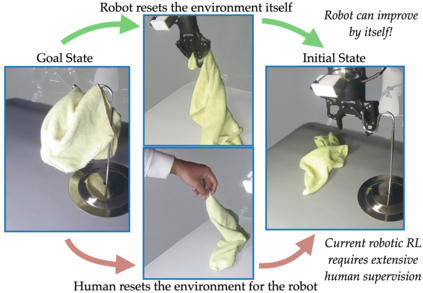
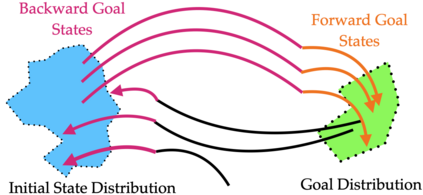
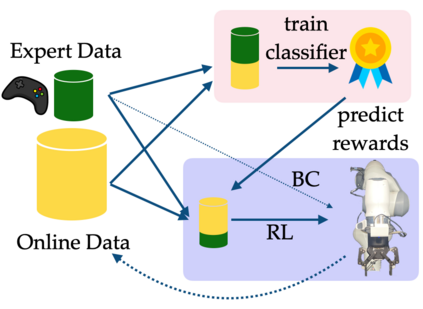
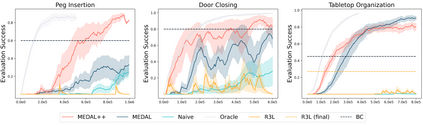
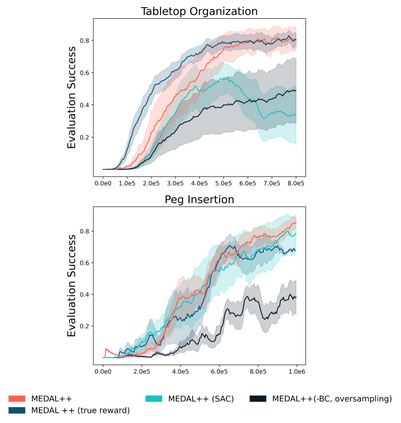
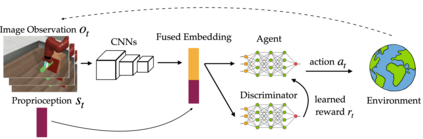
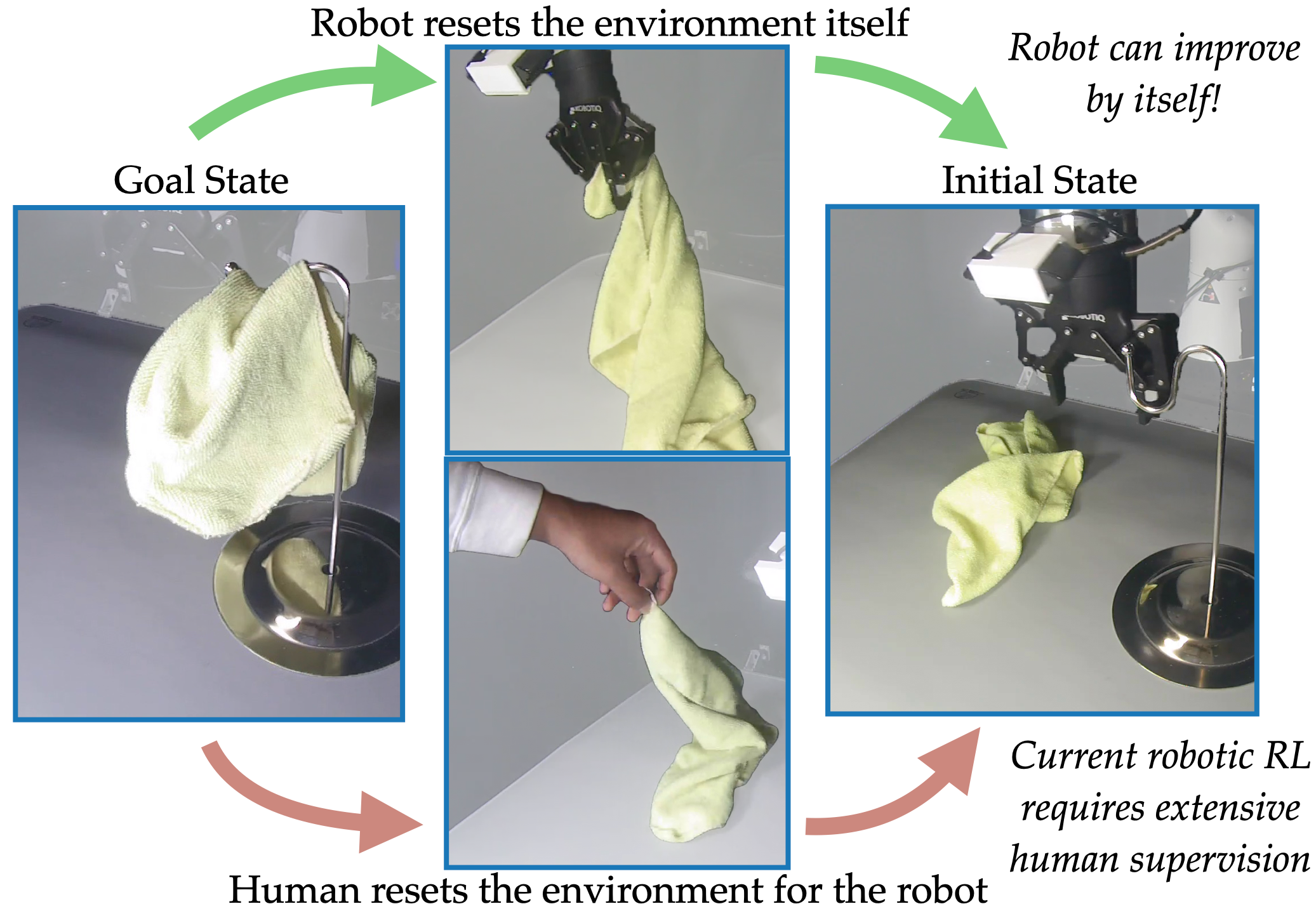
In imitation and reinforcement learning, the cost of human supervision limits the amount of data that robots can be trained on. An aspirational goal is to construct self-improving robots: robots that can learn and improve on their own, from autonomous interaction with minimal human supervision or oversight. Such robots could collect and train on much larger datasets, and thus learn more robust and performant policies. While reinforcement learning offers a framework for such autonomous learning via trial-and-error, practical realizations end up requiring extensive human supervision for reward function design and repeated resetting of the environment between episodes of interactions. In this work, we propose MEDAL++, a novel design for self-improving robotic systems: given a small set of expert demonstrations at the start, the robot autonomously practices the task by learning to both do and undo the task, simultaneously inferring the reward function from the demonstrations. The policy and reward function are learned end-to-end from high-dimensional visual inputs, bypassing the need for explicit state estimation or task-specific pre-training for visual encoders used in prior work. We first evaluate our proposed algorithm on a simulated non-episodic benchmark EARL, finding that MEDAL++ is both more data efficient and gets up to 30% better final performance compared to state-of-the-art vision-based methods. Our real-robot experiments show that MEDAL++ can be applied to manipulation problems in larger environments than those considered in prior work, and autonomous self-improvement can improve the success rate by 30-70% over behavior cloning on just the expert data. Code, training and evaluation videos along with a brief overview is available at: https://architsharma97.github.io/self-improving-robots/
翻译:在模仿和强化学习中,人的监管成本限制了机器人可以培训的数据数量。一个雄心勃勃的目标是建设自我改进机器人:机器人可以自己学习和改进,从最低限度的人类监督或监督进行自主互动。这样的机器人可以收集和训练更多的数据集,从而学习更有力和绩效的政策。虽然强化学习为通过试试和试探进行这种自主学习提供了一个框架,但实际实现最终需要广泛的人监督,以奖励功能设计以及反复在互动事件之间对环境的重新设置。在这个工作中,我们提议了MEDAL++,这是自我改进机器人系统的新设计:在开始时进行少量的专家演示,机器人可以自主地执行这项任务,同时从演示中推断出奖励功能。政策和奖励功能是从高层次的视觉输入中学习端到端,绕过明确的国家估算或特定任务前期在考虑的视觉解读器中进行改进。我们首先在模拟的自我评估中应用了真实的逻辑,然后在模拟的30-降压前的测试中,在模拟的测试中,在模拟的测试前期数据测试中,可以进行更精确的自我评估,在模拟的自我评估前期测试中,在模拟的测试前期的自我评估中,在模拟的自我评估中,可以进行更精确的自我定位中,在模拟的自我评估中,在模拟的测试前的自我评估中,在30-</s>