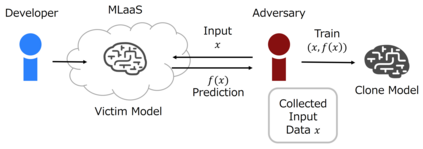
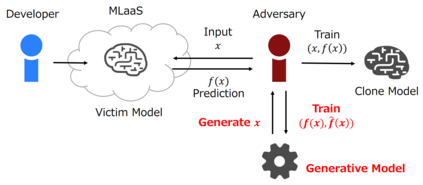
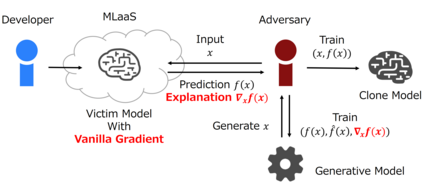
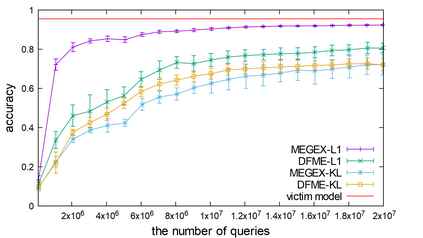
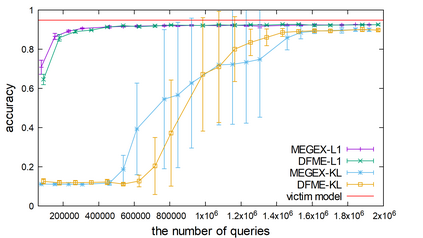
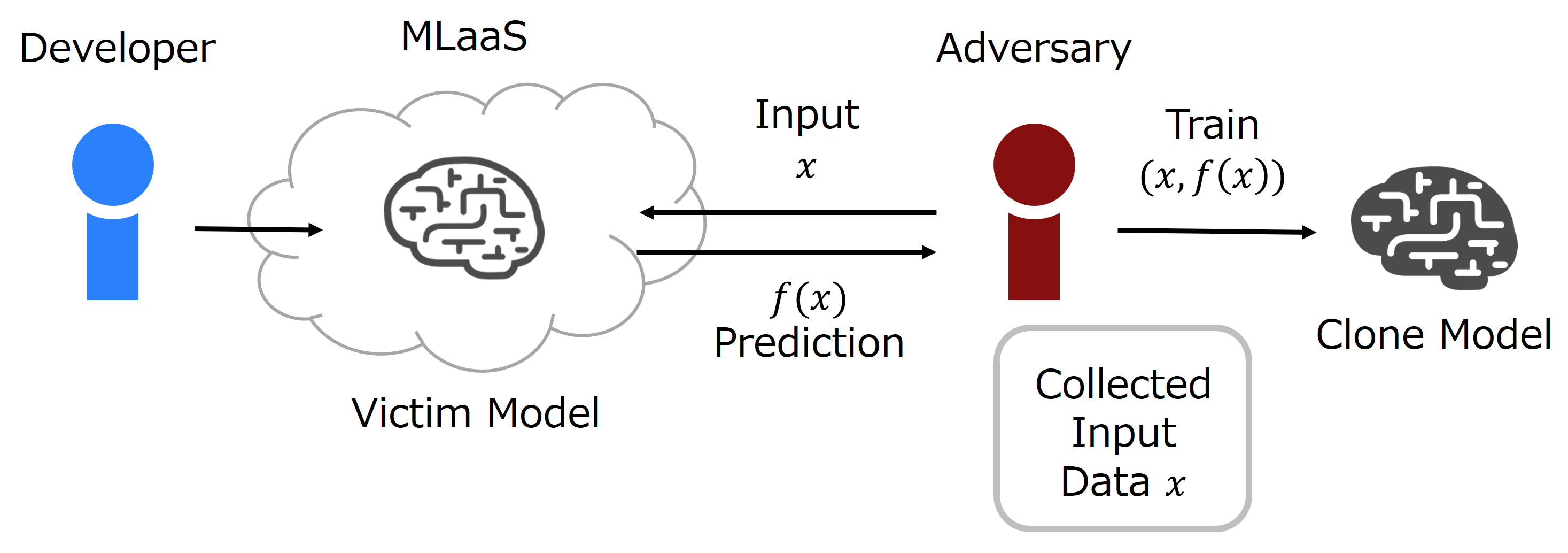
The advance of explainable artificial intelligence, which provides reasons for its predictions, is expected to accelerate the use of deep neural networks in the real world like Machine Learning as a Service (MLaaS) that returns predictions on queried data with the trained model. Deep neural networks deployed in MLaaS face the threat of model extraction attacks. A model extraction attack is an attack to violate intellectual property and privacy in which an adversary steals trained models in a cloud using only their predictions. In particular, a data-free model extraction attack has been proposed recently and is more critical. In this attack, an adversary uses a generative model instead of preparing input data. The feasibility of this attack, however, needs to be studied since it requires more queries than that with surrogate datasets. In this paper, we propose MEGEX, a data-free model extraction attack against a gradient-based explainable AI. In this method, an adversary uses the explanations to train the generative model and reduces the number of queries to steal the model. Our experiments show that our proposed method reconstructs high-accuracy models -- 0.97$\times$ and 0.98$\times$ the victim model accuracy on SVHN and CIFAR-10 datasets given 2M and 20M queries, respectively. This implies that there is a trade-off between the interpretability of models and the difficulty of stealing them.
翻译:可以解释的人工智能的推进,为预测提供了理由,预计将加速在现实世界中利用深层神经网络,例如机器学习服务(MLaaS),以经过训练的模型返回对数据作出的预测。在MLaaS部署的深神经网络面临模型抽取攻击的威胁。模型抽取攻击是一种攻击,目的是侵犯知识产权和隐私,其中敌人只用预测在云中窃取经过训练的模型。特别是最近提出了无数据模型抽取攻击,而且这种攻击更为关键。在这次攻击中,对手使用了基因模型,而不是编制投入数据。但是,这次攻击的可行性需要研究,因为它需要比对代孕数据集更多的查询。在本文件中,我们建议MEGEX对基于梯度的解释性人工智能进行无数据模型抽取攻击。在这个方法中,对手利用解释来训练基因化模型,减少窃取模型的查询次数。我们的实验表明,我们提出的方法对高精确性模型 -- 0.97美元/小时,而S-10-M的精确性(S-10-M)的精确性分别是S-58M数据解释。