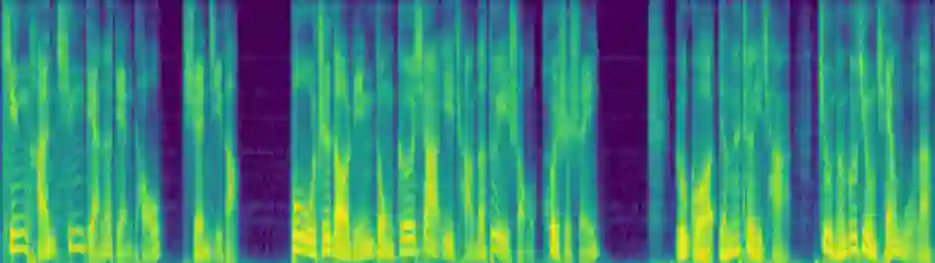
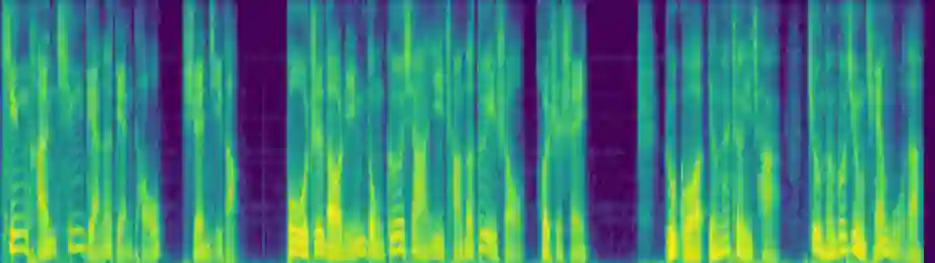
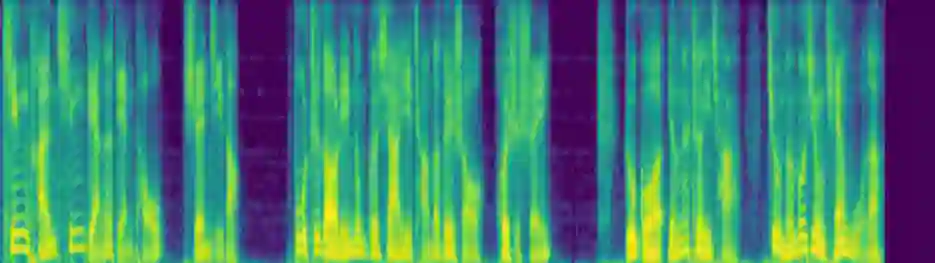
Humans often speak in a continuous manner which leads to coherent and consistent prosody properties across neighboring utterances. However, most state-of-the-art speech synthesis systems only consider the information within each sentence and ignore the contextual semantic and acoustic features. This makes it inadequate to generate high-quality paragraph-level speech which requires high expressiveness and naturalness. To synthesize natural and expressive speech for a paragraph, a context-aware speech synthesis system named MaskedSpeech is proposed in this paper, which considers both contextual semantic and acoustic features. Inspired by the masking strategy in the speech editing research, the acoustic features of the current sentence are masked out and concatenated with those of contextual speech, and further used as additional model input. The phoneme encoder takes the concatenated phoneme sequence from neighboring sentences as input and learns fine-grained semantic information from contextual text. Furthermore, cross-utterance coarse-grained semantic features are employed to improve the prosody generation. The model is trained to reconstruct the masked acoustic features with the augmentation of both the contextual semantic and acoustic features. Experimental results demonstrate that the proposed MaskedSpeech outperformed the baseline system significantly in terms of naturalness and expressiveness.
翻译:人类经常以连续的方式说话,从而在相邻的语句中形成一致和一致的流言特性。 然而,大多数最先进的语音合成系统只考虑每个句子中的信息,而忽略了语义和声学特点。 这使得它不足以产生高质量的段落级语言,这要求高清晰度和自然性。 要合成段落的自然和表达式语言,本文件提出了一种背景觉悟语音合成系统,它既考虑到背景语义特征,也考虑到声学特征。在语音编辑研究中遮盖战略的启发下,当前句子的声学特征被遮盖了,与背景语句的音调特征相融合,并被进一步用作额外的模型输入。 电话编码器将邻居语句中的相近音频序列作为输入,并从背景文字中学习精密的语义信息。 此外,本文件还采用了跨宽度、偏差的语义和声学特征来改进动的一代。 该模型经过训练,可以重建隐藏的声学特征,同时演示了背景语系基础和深层图像的升级。