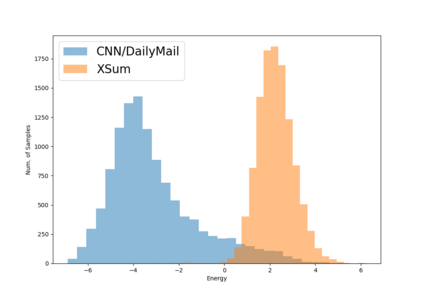
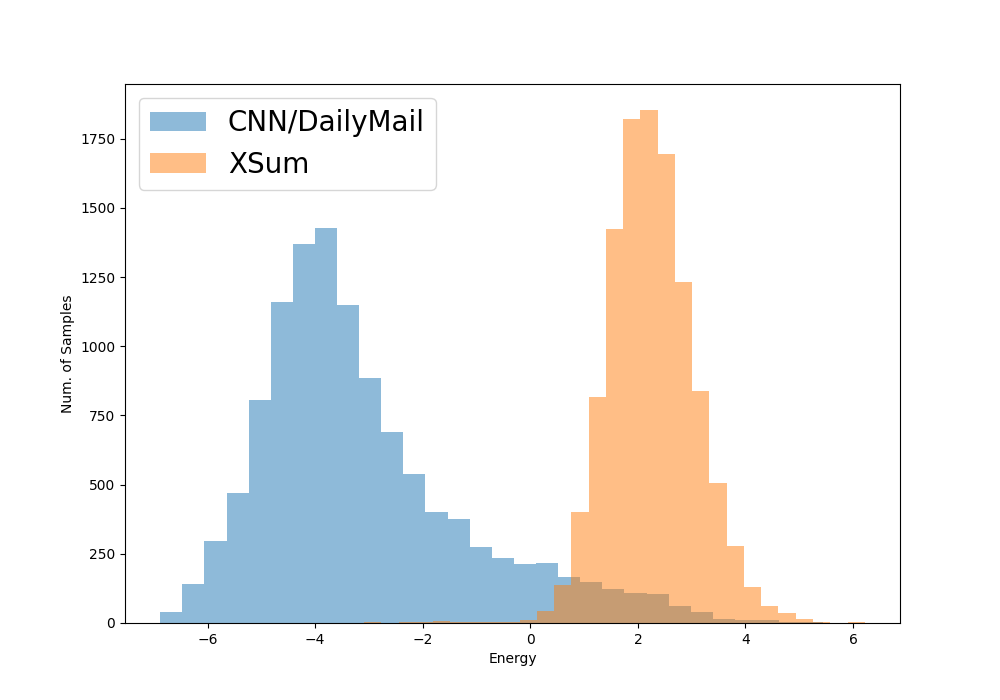
Current abstractive summarization systems present important weaknesses which prevent their deployment in real-world applications, such as the omission of relevant information and the generation of factual inconsistencies (also known as hallucinations). At the same time, automatic evaluation metrics such as CTC scores have been recently proposed that exhibit a higher correlation with human judgments than traditional lexical-overlap metrics such as ROUGE. In this work, we intend to close the loop by leveraging the recent advances in summarization metrics to create quality-aware abstractive summarizers. Namely, we propose an energy-based model that learns to re-rank summaries according to one or a combination of these metrics. We experiment using several metrics to train our energy-based re-ranker and show that it consistently improves the scores achieved by the predicted summaries. Nonetheless, human evaluation results show that the re-ranking approach should be used with care for highly abstractive summaries, as the available metrics are not yet sufficiently reliable for this purpose.
翻译:目前抽象总结系统存在严重的弱点,无法在现实世界应用中应用,例如不提供相关信息和产生事实不一致(也称为幻觉),同时,最近提出了诸如四氯化碳分数等自动评价指标,这些指标与人类判断的相关性高于传统词汇重叠指标(如ROUGE),在这项工作中,我们打算利用汇总计量的最新进展来创造有质量觉悟的抽象总结器,从而结束这一循环。也就是说,我们提议一种基于能源的模式,学会按照一种或多种指标的组合重新排列摘要。我们试验使用若干标准来培训基于能源的重新排序,并表明它一贯提高预测摘要的分数。然而,人类评价结果表明,重新排列方法应小心地用于非常抽象的摘要,因为现有的指标对于这一目的还不够可靠。