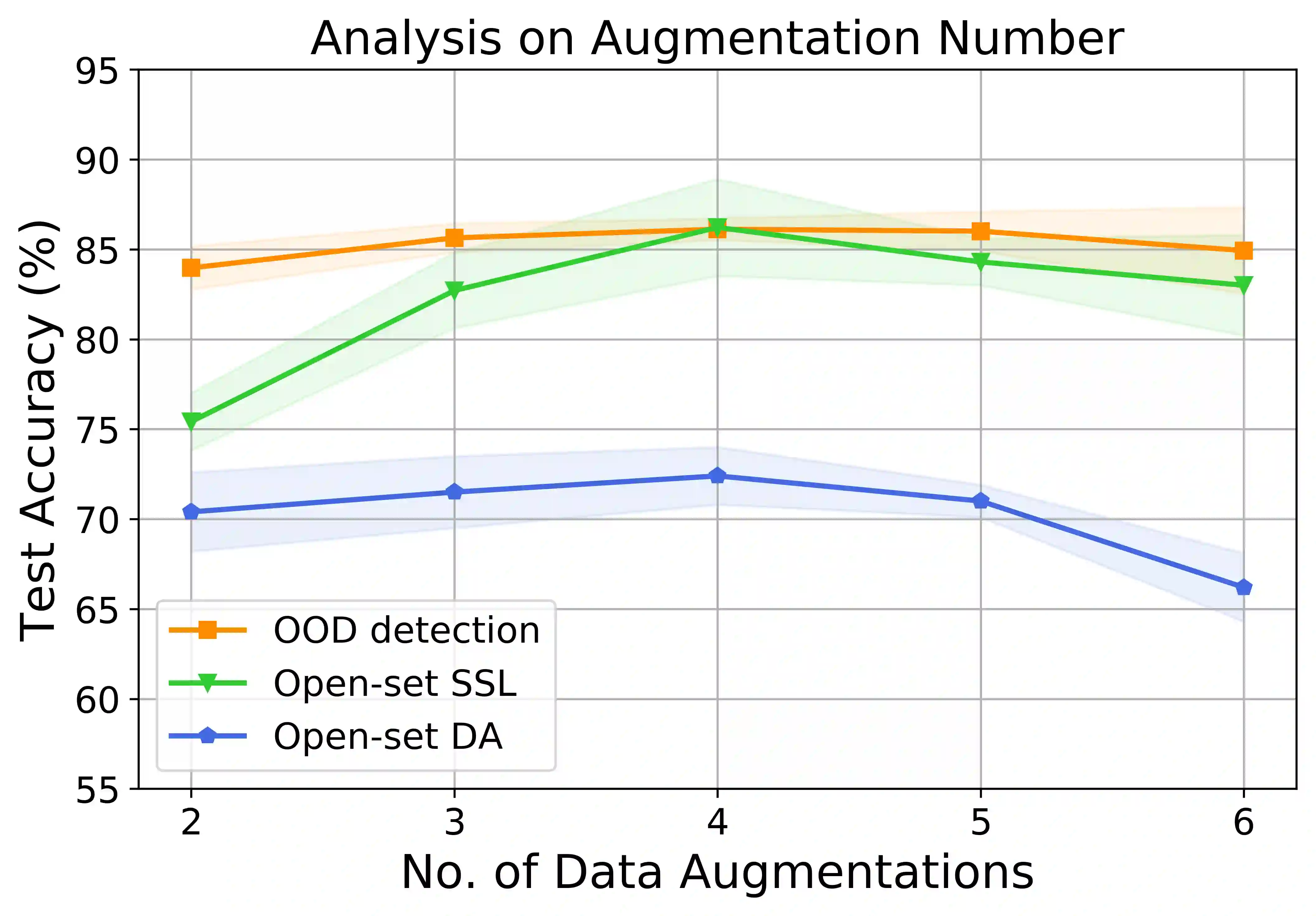
Machine learning models are vulnerable to Out-Of-Distribution (OOD) examples, such a problem has drawn much attention. However, current methods lack a full understanding of different types of OOD data: there are benign OOD data that can be properly adapted to enhance the learning performance, while other malign OOD data would severely degenerate the classification result. To Harness OOD data, this paper proposes HOOD method that can leverage the content and style from each image instance to identify benign and malign OOD data. Particularly, we design a variational inference framework to causally disentangle content and style features by constructing a structural causal model. Subsequently, we augment the content and style through an intervention process to produce malign and benign OOD data, respectively. The benign OOD data contain novel styles but hold our interested contents, and they can be leveraged to help train a style-invariant model. In contrast, the malign OOD data inherit unknown contents but carry familiar styles, by detecting them can improve model robustness against deceiving anomalies. Thanks to the proposed novel disentanglement and data augmentation techniques, HOOD can effectively deal with OOD examples in unknown and open environments, whose effectiveness is empirically validated in three typical OOD applications including OOD detection, open-set semi-supervised learning, and open-set domain adaptation.
翻译:机器学习模型很容易被流出(OOOD)的示例所忽略,这样的问题引起了很多注意。然而,目前的方法缺乏对不同类型OOD数据的全面理解:有好的OOOD数据可以适当调整以提高学习性能,而其他的恶意OOD数据会严重削弱分类结果。对 Harness OOOD数据,本文提出HOD方法,可以利用每个图像实例的内容和风格来利用内容和风格来识别良性和恶性OOOD数据。特别是,我们设计了一个因果分解内容和风格特点的变异推论框架,通过构建结构性因果模型。随后,我们通过一个干预过程来增加内容和风格,分别生成不良和良性OOD数据。良性OOD数据包含新风格,但保留我们感兴趣的内容,并且可以用来帮助培训风格变异模型。相比之下,恶意OOODD数据继承了未知的内容,但带有熟悉的风格,通过检测它们可以提高模型的坚固性,由于拟议的新颖的分解和数据递增强能力技术,OOOODD可以有效地在开放的域中进行实验性研究。