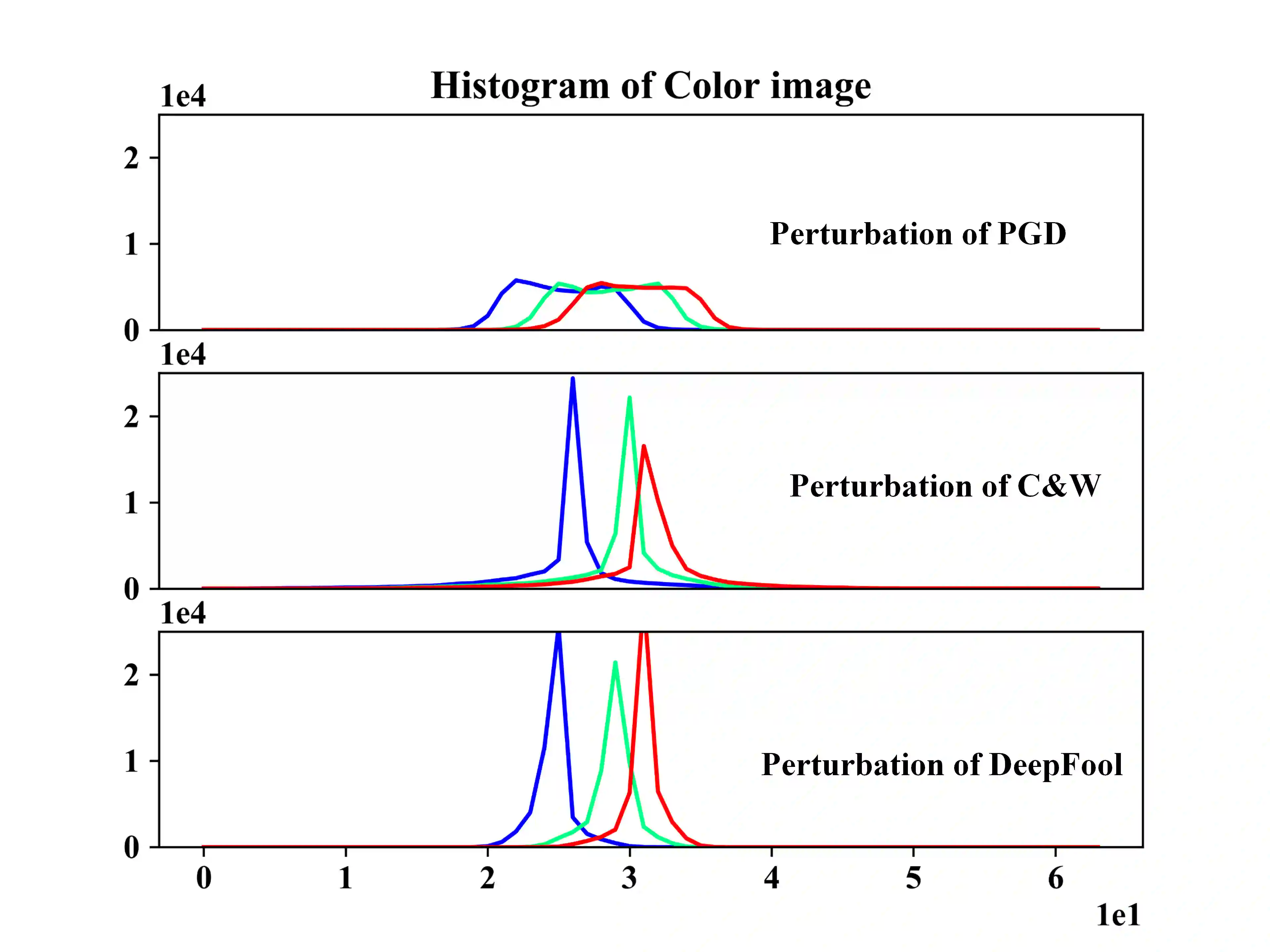
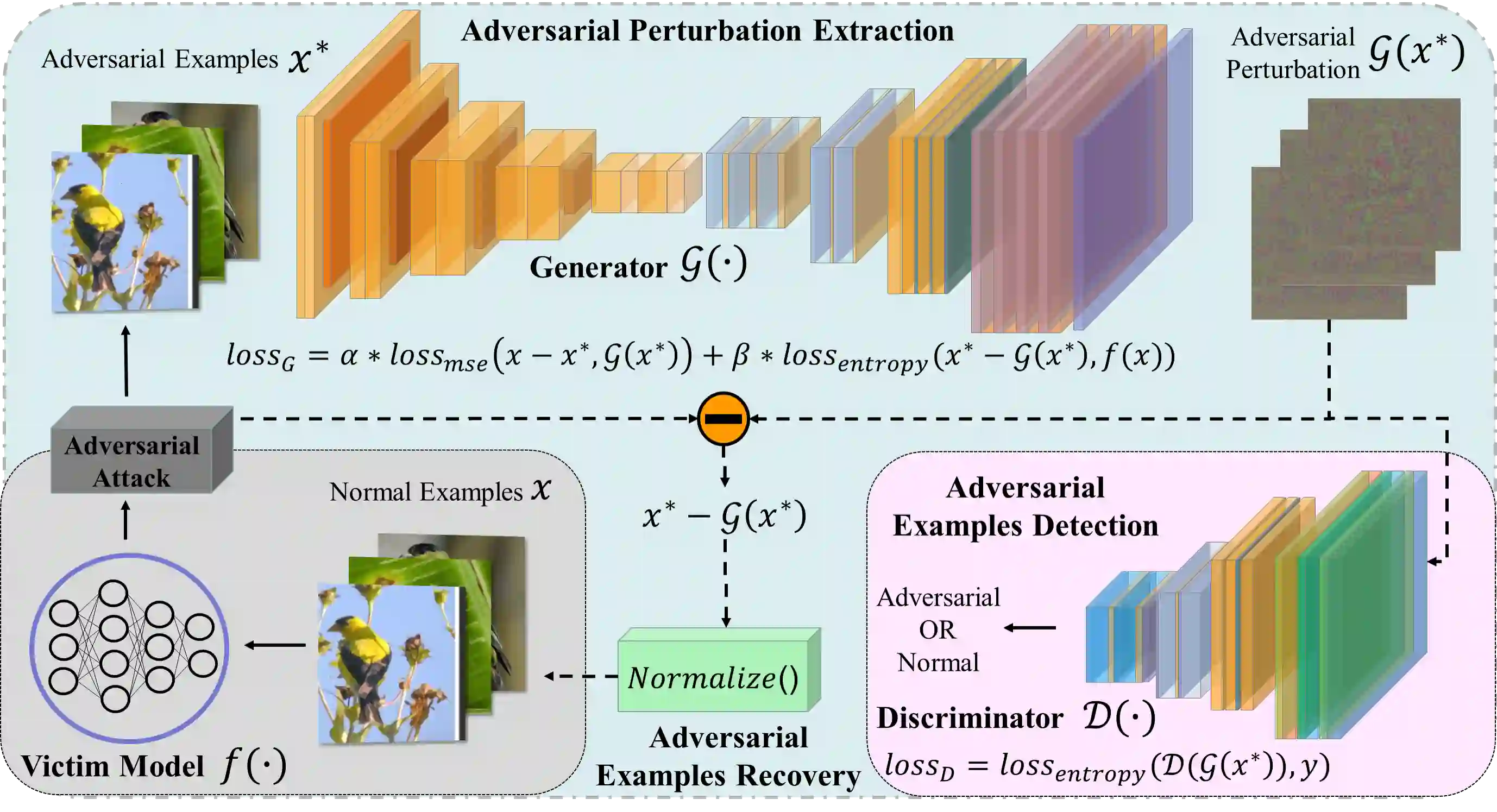
Deep neural networks (DNNs) have been shown to be vulnerable against adversarial examples (AEs) which are maliciously designed to fool target models. The normal examples (NEs) added with imperceptible adversarial perturbation, can be a security threat to DNNs. Although the existing AEs detection methods have achieved a high accuracy, they failed to exploit the information of the AEs detected. Thus, based on high-dimension perturbation extraction, we propose a model-free AEs detection method, the whole process of which is free from querying the victim model. Research shows that DNNs are sensitive to the high-dimension features. The adversarial perturbation hiding in the adversarial example belongs to the high-dimension feature which is highly predictive and non-robust. DNNs learn more details from high-dimension data than others. In our method, the perturbation extractor can extract the adversarial perturbation from AEs as high-dimension feature, then the trained AEs discriminator determines whether the input is an AE. Experimental results show that the proposed method can not only detect the adversarial examples with high accuracy, but also detect the specific category of the AEs. Meanwhile, the extracted perturbation can be used to recover the AEs to NEs.
翻译:深心神经网络(DNNS)被证明易受到恶意设计来愚弄目标模型的对抗性例子(AEs)的伤害。通常的例子(NES)加上了不易察觉的对抗性干扰,对DNNS来说可能是安全威胁。虽然现有的AES检测方法已经达到很高的精确度,但是它们未能利用所检测到的AES的信息。因此,根据高分层扰动提取法,我们建议一种无模型的AES检测方法,其整个过程都与询问受害者模型无关。研究显示,DNS(NES)对高分层特征十分敏感。在对抗性实例中隐藏的对DNNS的对抗性侵扰属于高分层特征,该特征具有高度预测性和非扰动性。DNNS从高分层数据中学习了更多的细节。在我们的方法中,渗透式提取器可以从AE中提取对AE的对准度,然后经过培训的AE分析者只能确定对高分级的测试结果是否为AE。