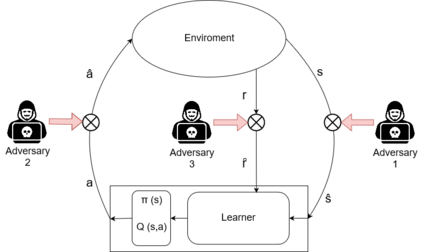
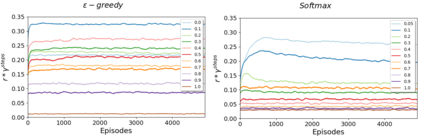
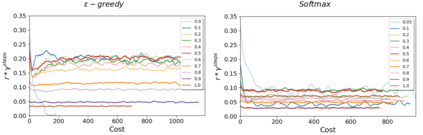
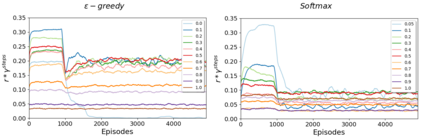
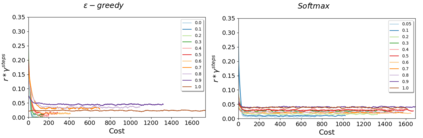
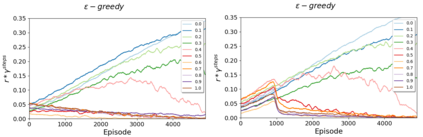
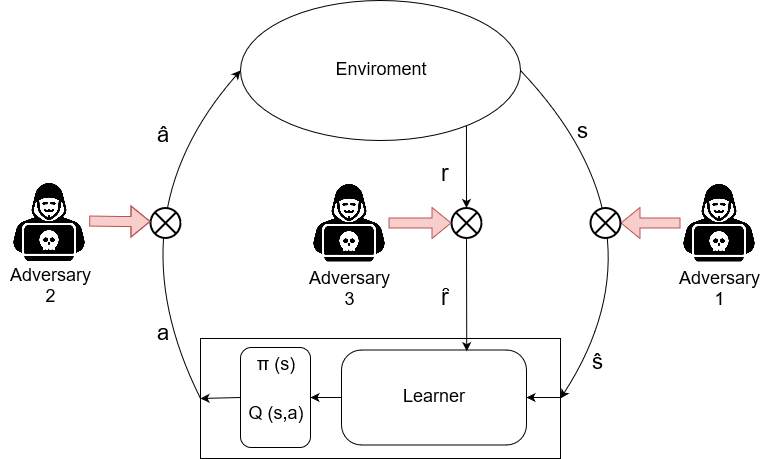
Reinforcement Learning (RL) algorithms have led to recent successes in solving complex games, such as Atari or Starcraft, and to a huge impact in real-world applications, such as cybersecurity or autonomous driving. In the side of the drawbacks, recent works have shown how the performance of RL algorithms decreases under the influence of soft changes in the reward function. However, little work has been done about how sensitive these disturbances are depending on the aggressiveness of the attack and the learning exploration strategy. In this paper, we propose to fill this gap in the literature analyzing the effects of different attack strategies based on reward perturbations, and studying the effect in the learner depending on its exploration strategy. In order to explain all the behaviors, we choose a sub-class of MDPs: episodic, stochastic goal-only-rewards MDPs, and in particular, an intelligible grid domain as a benchmark. In this domain, we demonstrate that smoothly crafting adversarial rewards are able to mislead the learner, and that using low exploration probability values, the policy learned is more robust to corrupt rewards. Finally, in the proposed learning scenario, a counterintuitive result arises: attacking at each learning episode is the lowest cost attack strategy.
翻译:强化学习(RL)算法导致最近成功解决了Atarri或Starcraft等复杂游戏(Atari或Starcraft)等复杂游戏,并在网络安全或自主驾驶等现实应用中产生了巨大影响。在缺点的另一方面,最近的工程表明,在奖励功能的软变化影响下,RL算法的表现如何在奖励功能的软变化的影响下下降。然而,关于这些扰动的敏感程度如何取决于攻击的侵略性和学习探索战略,这些攻击性攻击性攻击性攻击战略取决于攻击攻击的侵略性和学习探索策略。在本文件中,我们提议填补文献分析不同攻击战略(例如Atarri或Starcraft)影响的这一差距,对不同攻击战略(例如Atarri 或Starcccraft ) 影响的影响进行了巨大影响,以及实际学习者根据探索战略的策略来研究。为了解释所有的行为,我们选择了RLL算算算算算算算算算法的亚值,我们选择了MDP的子类:在奖励的分数上,我们选择了一个最小的学习计划是最低的策略。最后,学习一个最低的策略是学习计划。 学习一个最低的策略。 学习计划。 学习计划是: 学习一个最低的, 学习计划。 学习 学习 学习 学习一个最低的策略是: 学习一个最低的, 学习计划。