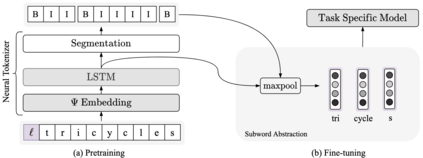
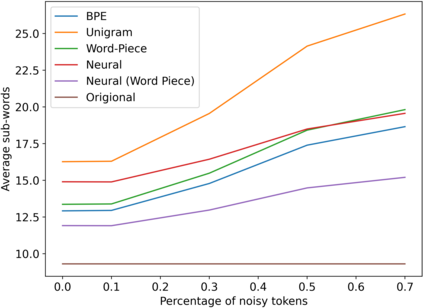
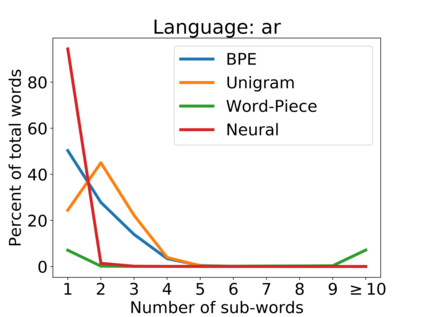
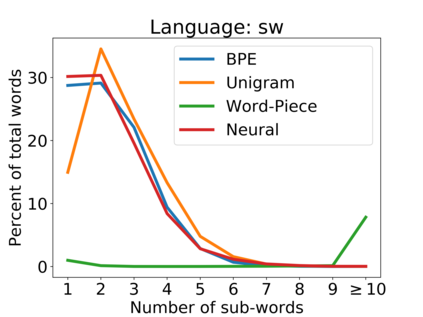
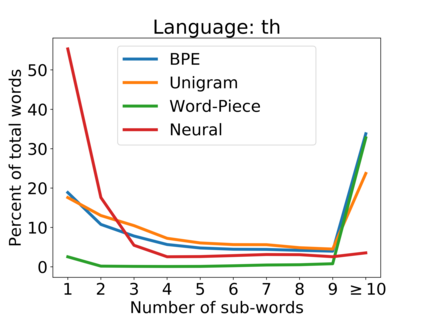
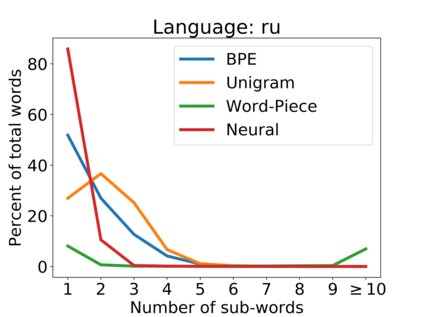
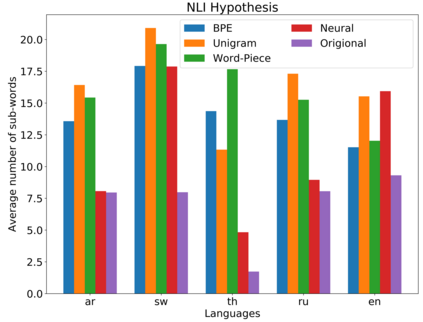
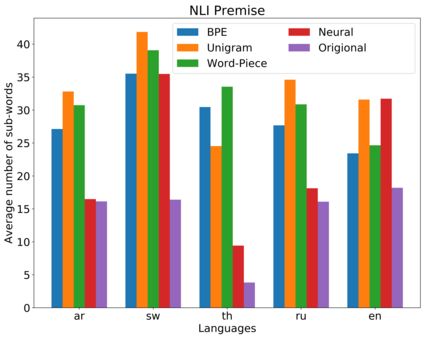
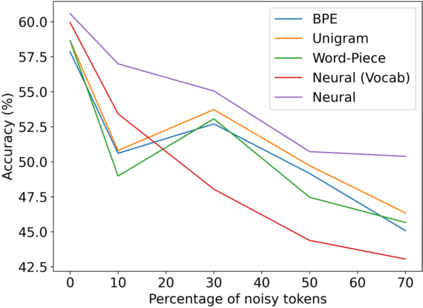
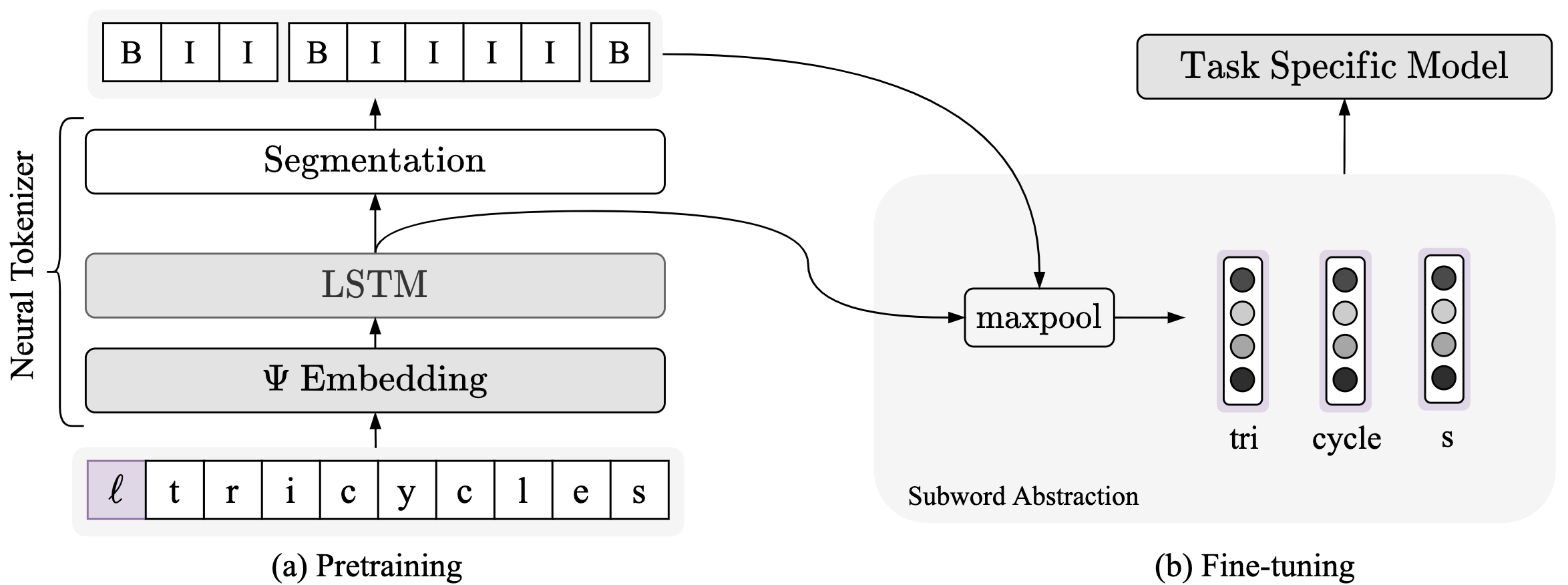
Subword tokenization is a commonly used input pre-processing step in most recent NLP models. However, it limits the models' ability to leverage end-to-end task learning. Its frequency-based vocabulary creation compromises tokenization in low-resource languages, leading models to produce suboptimal representations. Additionally, the dependency on a fixed vocabulary limits the subword models' adaptability across languages and domains. In this work, we propose a vocabulary-free neural tokenizer by distilling segmentation information from heuristic-based subword tokenization. We pre-train our character-based tokenizer by processing unique words from multilingual corpus, thereby extensively increasing word diversity across languages. Unlike the predefined and fixed vocabularies in subword methods, our tokenizer allows end-to-end task learning, resulting in optimal task-specific tokenization. The experimental results show that replacing the subword tokenizer with our neural tokenizer consistently improves performance on multilingual (NLI) and code-switching (sentiment analysis) tasks, with larger gains in low-resource languages. Additionally, our neural tokenizer exhibits a robust performance on downstream tasks when adversarial noise is present (typos and misspelling), further increasing the initial improvements over statistical subword tokenizers.
翻译:子字质化是最近NLP模式中常用的一种输入预处理步骤。 但是, 它限制了模型利用端到端任务学习的能力。 以频率为基础的词汇创建会以低资源语言进行折叠化, 导致出现亚最佳表示方式。 此外, 依赖固定词汇限制了子字型在语言和领域的适应性。 在这项工作中, 我们提出一个无词汇的神经象征器, 蒸馏基于超光速的子字质化的分解信息 。 我们通过处理多种语言中独特的单词, 从而广泛增加不同语言的字面多样性, 来对基于字符的象征器进行预先培训 。 与子字型方法中预先定义和固定的词汇不同, 我们的代名化器允许端到端任务学习, 导致最佳的特定任务代名化 。 实验结果表明, 用我们的神经象征器取代子字质代名化器, 不断提高多语言( NLI) 和代码转换( 流化分析) 的性能效性能, 在低资源语言中取得更大的成果 。 此外, 我们的质质质质质质质质质材料展示展示了在下级噪音时, 的初始任务将不断增强。