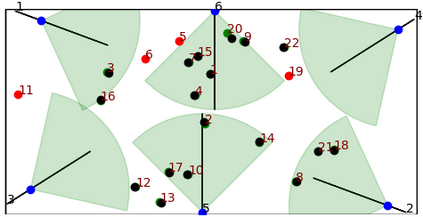
Active Multi-Object Tracking (AMOT) is a task where cameras are controlled by a centralized system to adjust their poses automatically and collaboratively so as to maximize the coverage of targets in their shared visual field. In AMOT, each camera only receives partial information from its observation, which may mislead cameras to take locally optimal action. Besides, the global goal, i.e., maximum coverage of objects, is hard to be directly optimized. To address the above issues, we propose a coordinate-aligned multi-camera collaboration system for AMOT. In our approach, we regard each camera as an agent and address AMOT with a multi-agent reinforcement learning solution. To represent the observation of each agent, we first identify the targets in the camera view with an image detector, and then align the coordinates of the targets in 3D environment. We define the reward of each agent based on both global coverage as well as four individual reward terms. The action policy of the agents is derived with a value-based Q-network. To the best of our knowledge, we are the first to study the AMOT task. To train and evaluate the efficacy of our system, we build a virtual yet credible 3D environment, named "Soccer Court", to mimic the real-world AMOT scenario. The experimental results show that our system achieves a coverage of 71.88%, outperforming the baseline method by 8.9%.
翻译:主动多目标跟踪(AMOT)是一项任务,即照相机由中央系统控制,以自动和协作地调整其姿势,从而最大限度地扩大其共同视觉领域目标的覆盖范围。在AMOT中,每部照相机只能从观察中得到部分信息,这可能误导照相机,从而采取当地最佳行动。此外,全球目标,即物体的最大覆盖范围,很难直接优化。为了解决上述问题,我们建议为AMOT建立一个协调的多镜头合作系统。在我们的方法中,我们把每部照相机视为一个代理机,用多试剂强化学习解决方案处理AMOT。为了代表每个代理机的观测,我们首先用图像探测器确定摄像头视图中的目标,然后在3D环境中调整目标的坐标。我们根据全球覆盖面和四个个人奖赏条件来界定每个代理机的奖赏。为了解决上述问题,我们提议了一个基于价值的Q-网络,我们最了解的是,我们首先研究AMOT任务。为了培训和评估我们系统的效率,我们先用图像探测器的图像视图,我们建立虚拟的AOT-MV 3的模型显示我们的真实环境。我们的一个虚拟的8-MIS的基线,我们用来显示了8OD的实验性环境。