
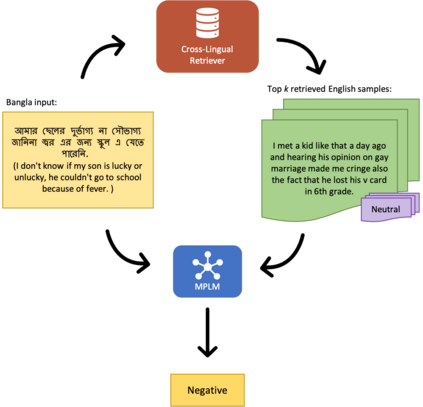
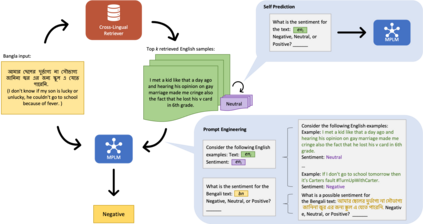
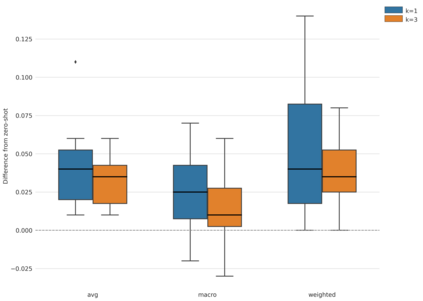
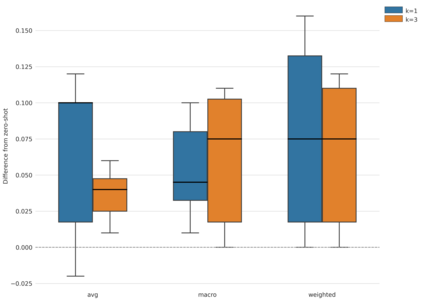
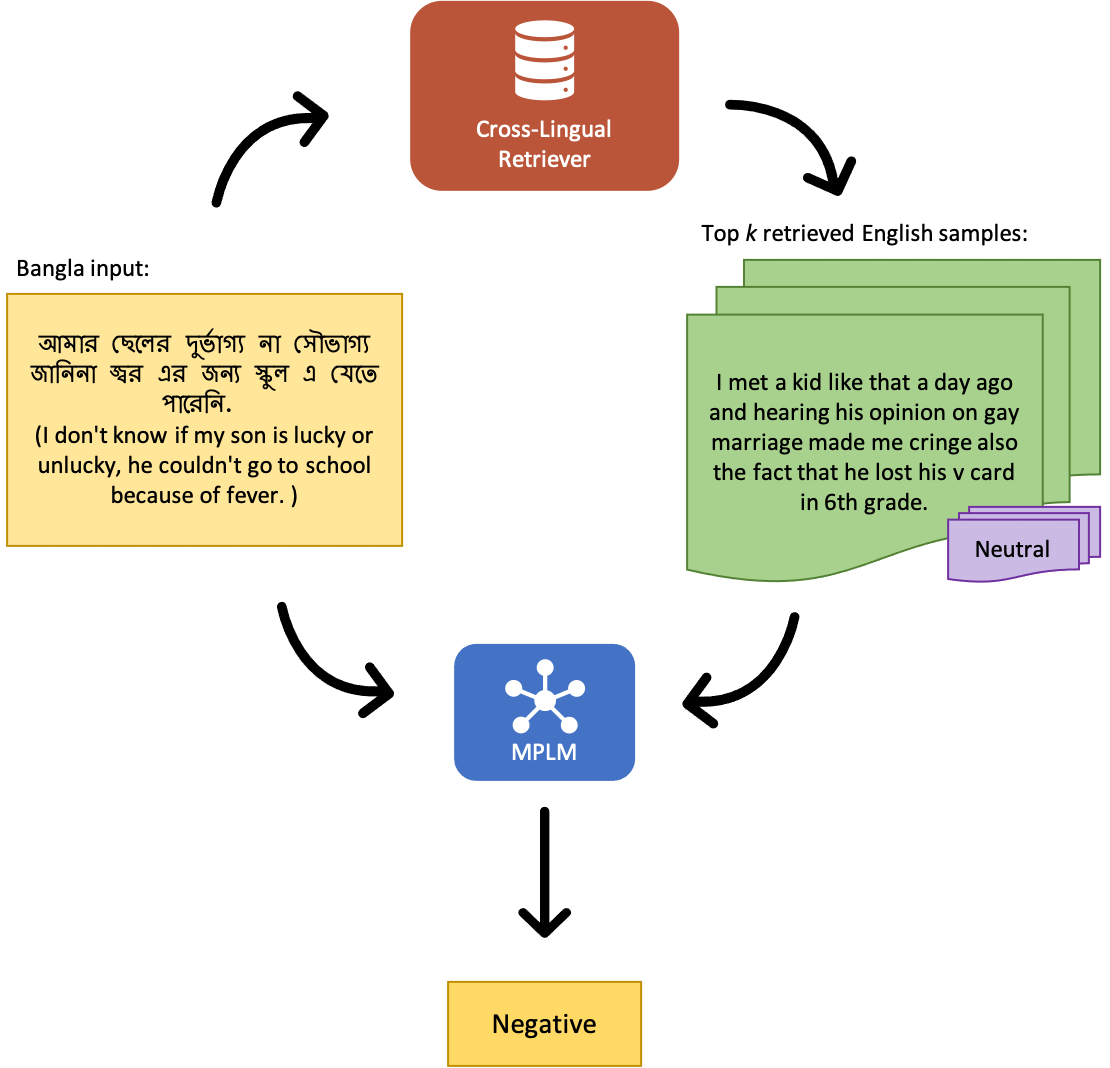
The promise of Large Language Models (LLMs) in Natural Language Processing has often been overshadowed by their limited performance in low-resource languages such as Bangla. To address this, our paper presents a pioneering approach that utilizes cross-lingual retrieval augmented in-context learning. By strategically sourcing semantically similar prompts from high-resource language, we enable multilingual pretrained language models (MPLMs), especially the generative model BLOOMZ, to successfully boost performance on Bangla tasks. Our extensive evaluation highlights that the cross-lingual retrieval augmented prompts bring steady improvements to MPLMs over the zero-shot performance.
翻译:暂无翻译
相关内容
专知会员服务
54+阅读 · 2020年1月30日
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
0+阅读 · 2023年12月20日
Arxiv
0+阅读 · 2023年12月19日
User Authentication and Identity Inconsistency Detection via Mouse-trajectory Similarity Measurement
Arxiv
0+阅读 · 2023年12月16日
Arxiv
0+阅读 · 2023年12月15日
Arxiv
0+阅读 · 2023年12月15日
Arxiv
13+阅读 · 2020年12月3日



相关VIP内容
专知会员服务
54+阅读 · 2020年1月30日
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯