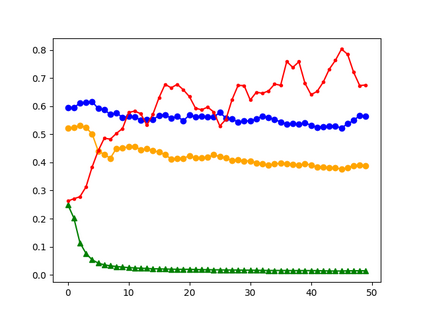
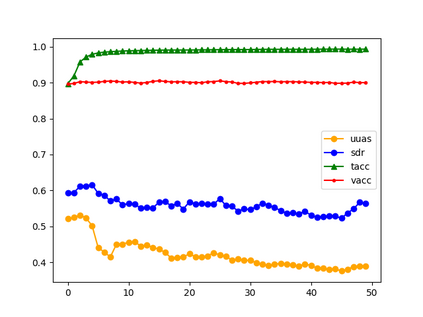
Large language models (LLMs) have been reported to have strong performance on natural language processing tasks. However, performance metrics such as accuracy do not measure the quality of the model in terms of its ability to robustly represent complex linguistic structure. Further, the sheer size of LLMs makes it difficult to analyse them using standard robustness evaluation methods. In this work, we propose a framework to evaluate the robustness of linguistic representations using probing tasks. We argue that a robust linguistic model is one that is able to robustly and efficiently represent complex syntactic structure underlying the data distribution and propose appropriate robustness measures. We leverage recent advances in extracting emergent linguistic constructs from LLMs and apply syntax-preserving perturbations to test the stability of these constructs in order to better understand the representations learned by LLMs. Empirically, we study the performance of four LLMs across six different corpora on the proposed robustness measures. We provide evidence that context-free representation (e.g., GloVE) are in some cases competitive with context-dependent representations from modern LLMs (e.g., BERT), yet equally brittle to syntax-preserving manipulations. Emergent syntactic representations in neural networks are brittle, thus our work poses the attention on the risk of comparing such structures to those that are object of a long lasting debate in linguistics.
翻译:据报道,大型语言模型(LLMS)在自然语言处理任务方面表现良好,但是,准确性等业绩衡量标准不能衡量该模型的质量,因为它能够强有力地代表复杂的语言结构。此外,由于LLMS的庞大规模,因此很难使用标准的稳健性评价方法来分析这些模型。在这项工作中,我们提出了一个框架,以利用探测任务来评价语言代表的稳健性。我们争辩说,一个强有力的语言模型能够强有力和高效地代表数据分配的复杂综合结构,并提出适当的稳健措施。我们利用最近在从LLMS提取新兴语言结构方面取得的进步,并运用语法保护干扰来测试这些结构的稳定性,以便更好地理解LMS所学到的表述。我们很生动地研究了六个不同的公司群群中四个LMS的绩效。我们提供了证据,证明在有些情况下,无背景代表(例如Glove)具有竞争性,而现代LMS(eg.BERT)根据背景进行的代表具有竞争力,因此,这些网络也具有长期性操纵的风险。