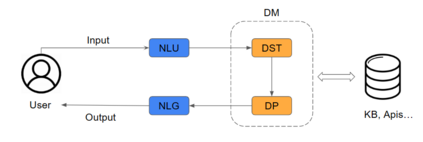
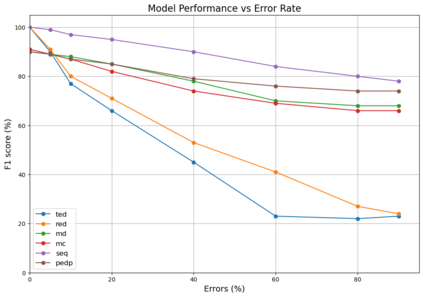
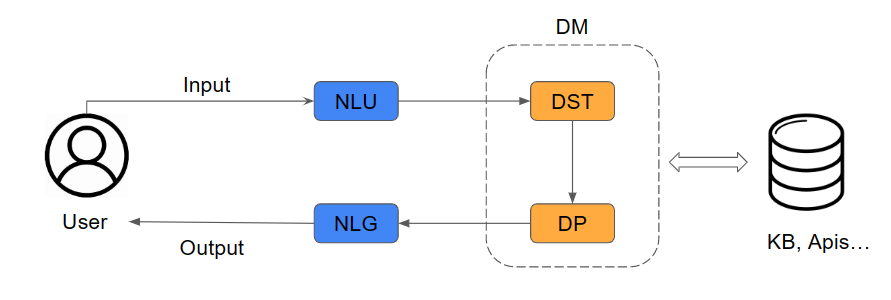
Task-oriented dialogue systems (TODS) have become crucial for users to interact with machines and computers using natural language. One of its key components is the dialogue manager, which guides the conversation towards a good goal for the user by providing the best possible response. Previous works have proposed rule-based systems (RBS), reinforcement learning (RL), and supervised learning (SL) as solutions for the correct dialogue management; in other words, select the best response given input by the user. However, this work argues that the leading cause of DMs not achieving maximum performance resides in the quality of the datasets rather than the models employed thus far; this means that dataset errors, like mislabeling, originate a large percentage of failures in dialogue management. We studied the main errors in the most widely used datasets, Multiwoz 2.1 and SGD, to demonstrate this hypothesis. To do this, we have designed a synthetic dialogue generator to fully control the amount and type of errors introduced in the dataset. Using this generator, we demonstrated that errors in the datasets contribute proportionally to the performance of the models
翻译:暂无翻译