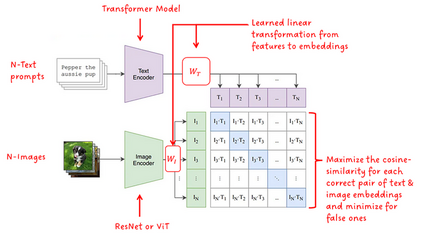
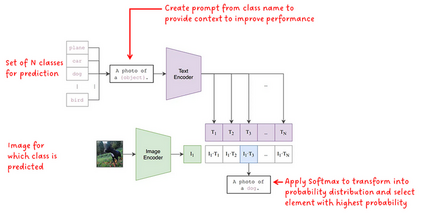
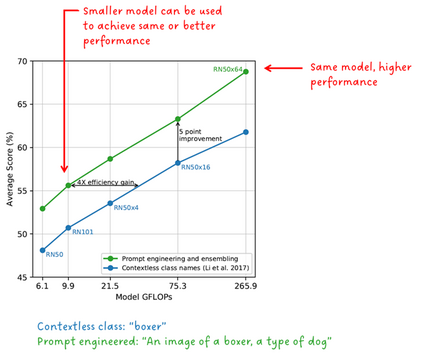
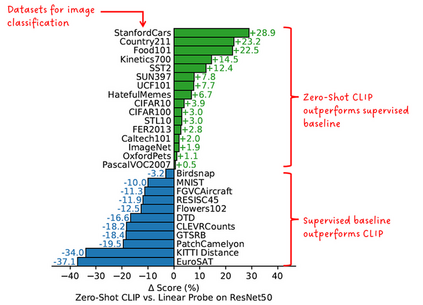
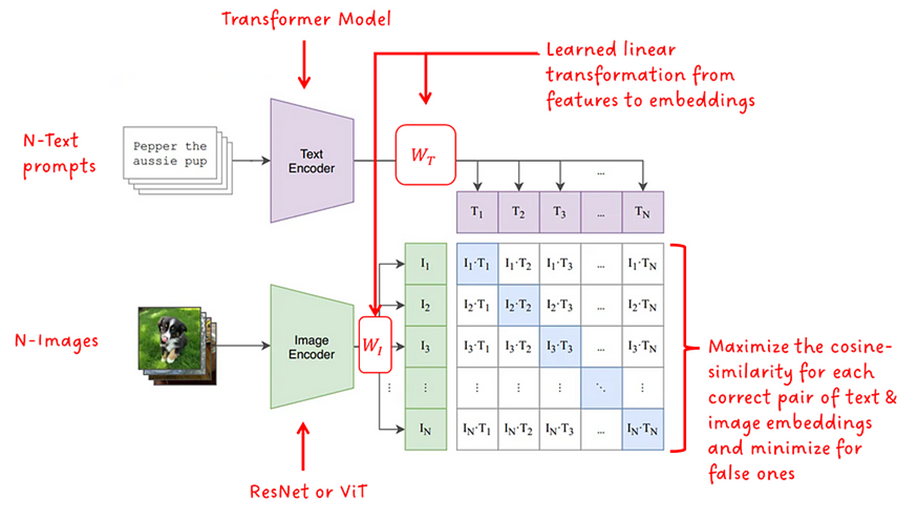
Photo search, the task of retrieving images based on textual queries, has witnessed significant advancements with the introduction of CLIP (Contrastive Language-Image Pretraining) model. CLIP leverages a vision-language pre training approach, wherein it learns a shared representation space for images and text, enabling cross-modal understanding. This model demonstrates the capability to understand the semantic relationships between diverse image and text pairs, allowing for efficient and accurate retrieval of images based on natural language queries. By training on a large-scale dataset containing images and their associated textual descriptions, CLIP achieves remarkable generalization, providing a powerful tool for tasks such as zero-shot learning and few-shot classification. This abstract summarizes the foundational principles of CLIP and highlights its potential impact on advancing the field of photo search, fostering a seamless integration of natural language understanding and computer vision for improved information retrieval in multimedia applications
翻译:暂无翻译