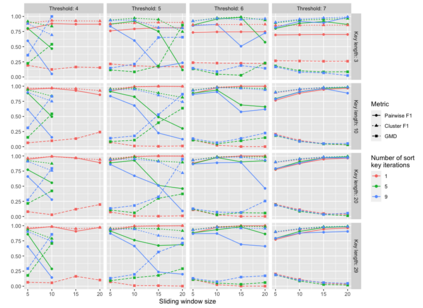
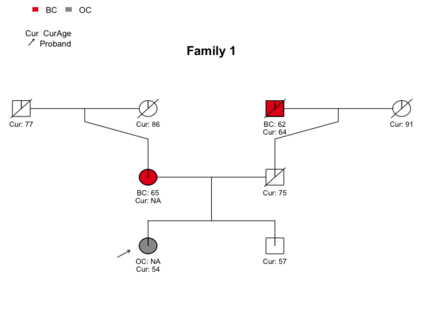
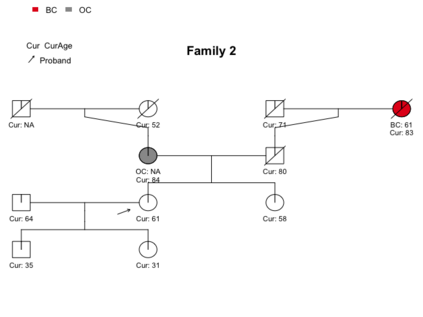
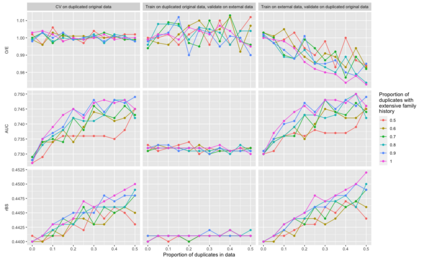
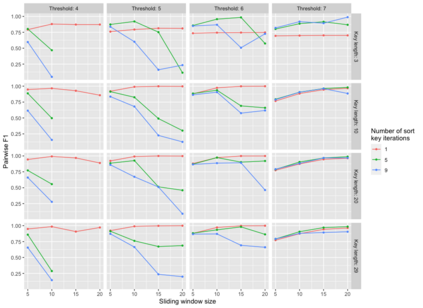
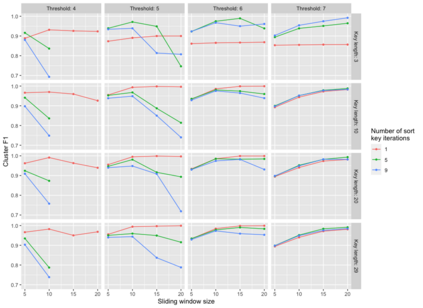
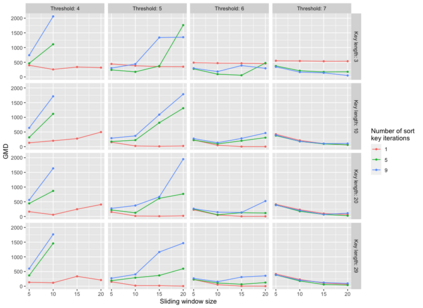
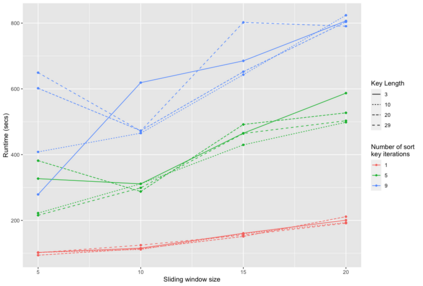
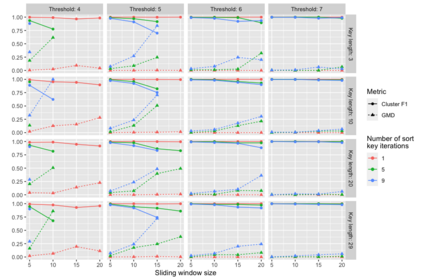
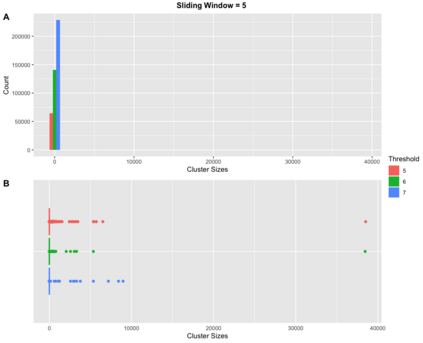
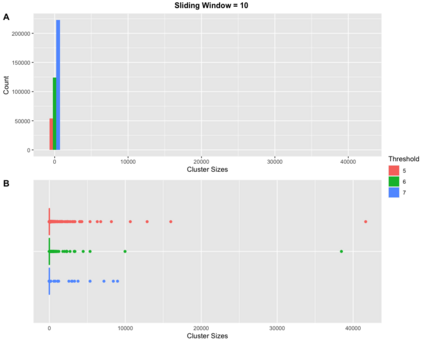
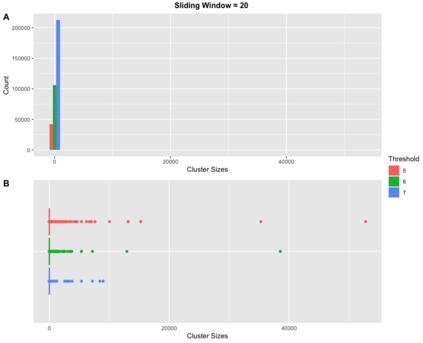
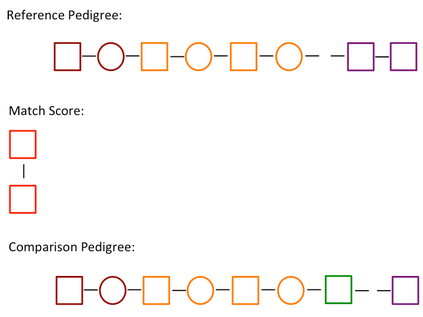
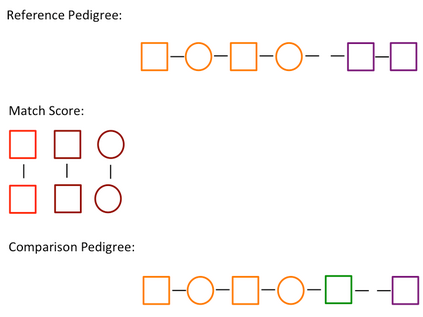
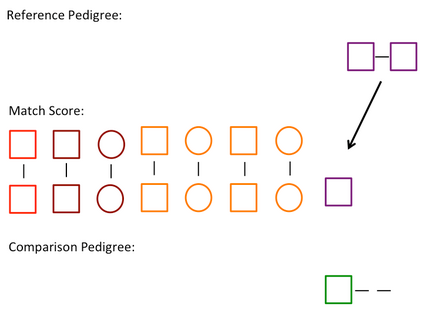
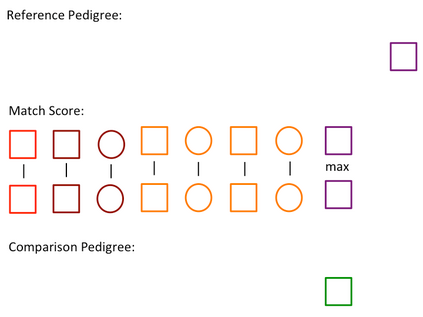
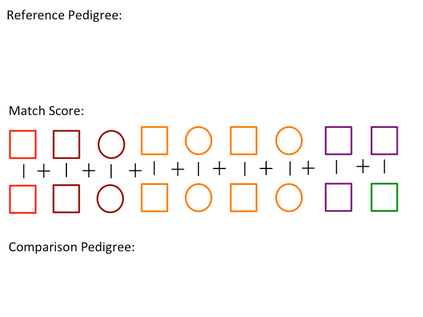
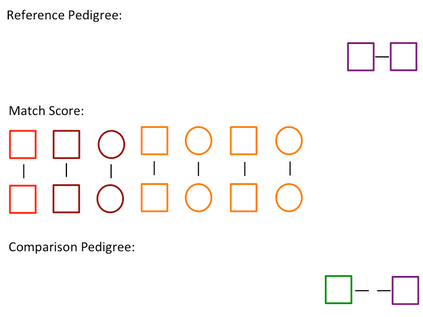
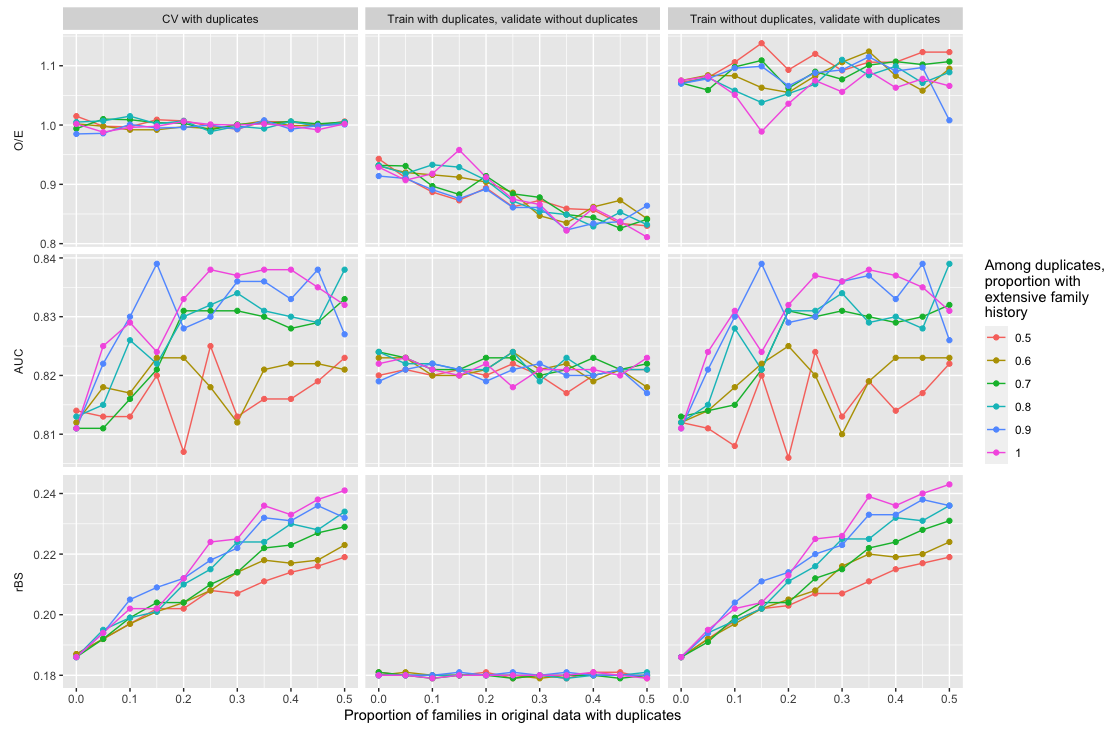
Pedigree data contain family history information that is used to analyze hereditary diseases. These clinical data sets may contain duplicate records due to the same family visiting a clinic multiple times or a clinician entering multiple versions of the family for testing purposes. Inferences drawn from the data or using them for training or validation without removing the duplicates could lead to invalid conclusions, and hence identifying the duplicates is essential. Since family structures can be complex, existing deduplication algorithms cannot be applied directly. We first motivate the importance of deduplication by examining the impact of pedigree duplicates on the training and validation of a familial risk prediction model. We then introduce an unsupervised algorithm, which we call SNIP (Sorted NeIghborhood for Pedigrees), that builds on the sorted neighborhood method to efficiently find and classify pairwise comparisons by leveraging the inherent hierarchical nature of the pedigrees. We conduct a simulation study to assess the performance of the algorithm and find parameter configurations where the algorithm is able to accurately detect the duplicates. We then apply the method to data from the Risk Service, which includes over 300,000 pedigrees at high risk of hereditary cancers, and uncover large clusters of potential duplicate families. After removing 104,520 pedigrees (33% of original data), the resulting Risk Service dataset can now be used for future analysis, training, and validation. The algorithm is available as an R package snipR available at https://github.com/bayesmendel/snipR.
翻译:Pedigree数据包含用于分析遗传疾病的家庭历史信息。这些临床数据集可能包含重复记录,原因是同一个家庭多次访问诊所或进入多种家庭版本以进行测试。从数据中得出的推论,或将其用于培训或验证而不去除重复数据,可能会导致无效的结论,因此确定重复数据至关重要。由于家庭结构可能很复杂,现有的解析算法无法直接应用。我们首先通过研究小拼图复制对培训和验证家庭风险预测模型的影响来激励消解的重要性。然后我们引入一种未经监督的算法,我们称之为SNIP(Sorted NeIghborhood for Pedigrees),这种算法建立在分类的邻里方法上,以便通过利用内部结构的等级性来有效查找和分类比较。我们进行模拟研究,以评估算法的性表现,并在可精确检测复制的20种序列中找到参数配置。我们然后将这一方法应用于风险系统的数据,在风险系统(Snoted Negrational com)中,在原始的40万种风险组中,在原始的Rigregressreal 中,后,在利用了104种前的风险系统。