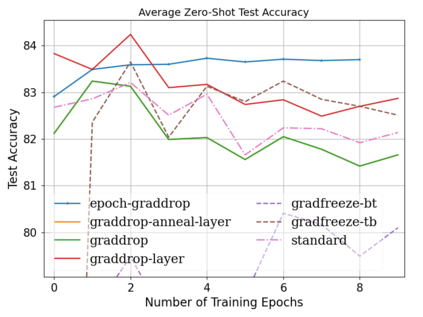
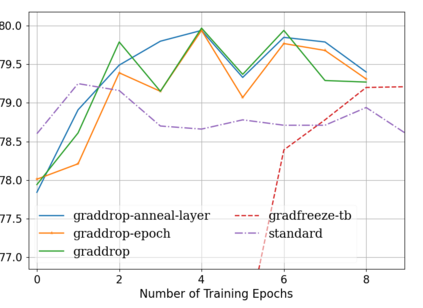
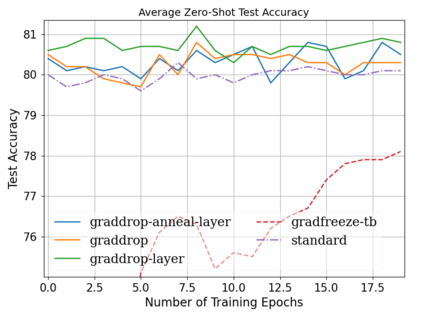
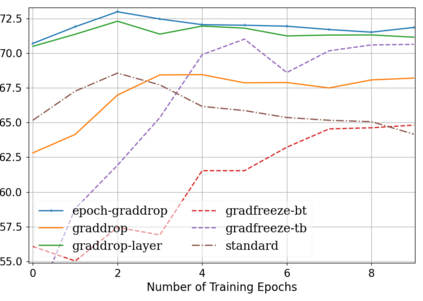
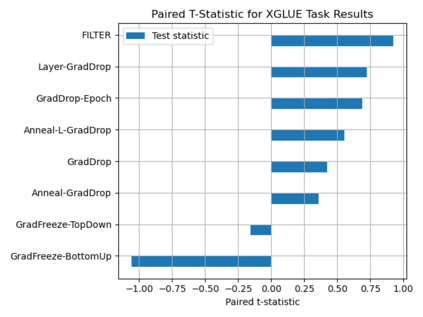
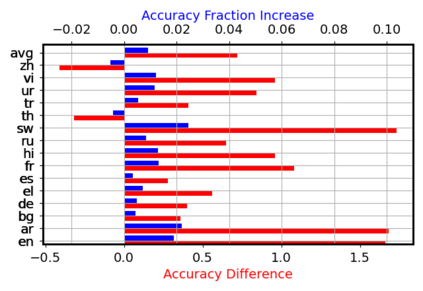
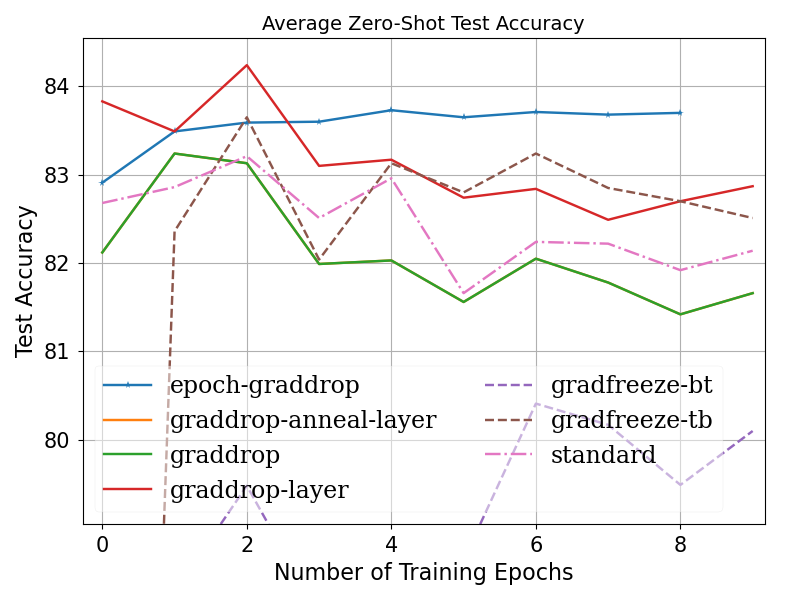
Fine-tuning pretrained self-supervised language models is widely adopted for transfer learning to downstream tasks. Fine-tuning can be achieved by freezing gradients of the pretrained network and only updating gradients of a newly added classification layer, or by performing gradient updates on all parameters. Gradual unfreezing makes a trade-off between the two by gradually unfreezing gradients of whole layers during training. This has been an effective strategy to trade-off between storage and training speed with generalization performance. However, it is not clear whether gradually unfreezing layers throughout training is optimal, compared to sparse variants of gradual unfreezing which may improve fine-tuning performance. In this paper, we propose to stochastically mask gradients to regularize pretrained language models for improving overall fine-tuned performance. We introduce GradDrop and variants thereof, a class of gradient sparsification methods that mask gradients during the backward pass, acting as gradient noise. GradDrop is sparse and stochastic unlike gradual freezing. Extensive experiments on the multilingual XGLUE benchmark with XLMR-Large show that GradDrop is competitive against methods that use additional translated data for intermediate pretraining and outperforms standard fine-tuning and gradual unfreezing. A post-analysis shows how GradDrop improves performance with languages it was not trained on, such as under-resourced languages.
翻译:暂无翻译