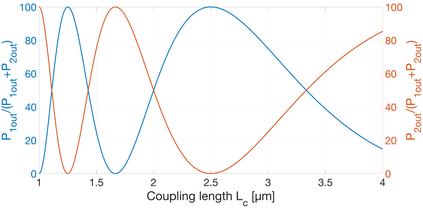
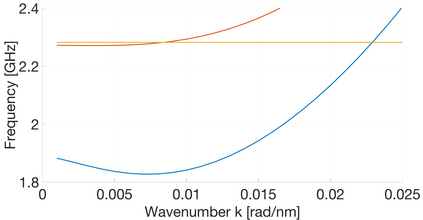
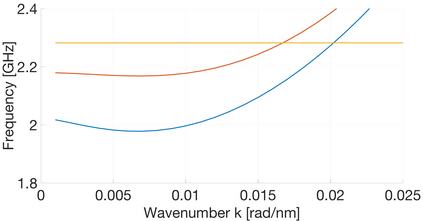
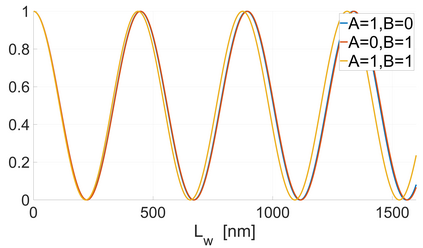
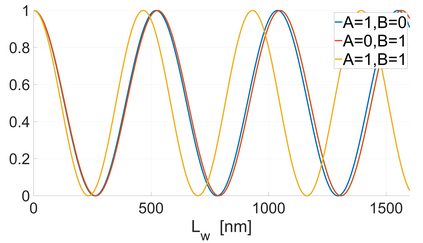
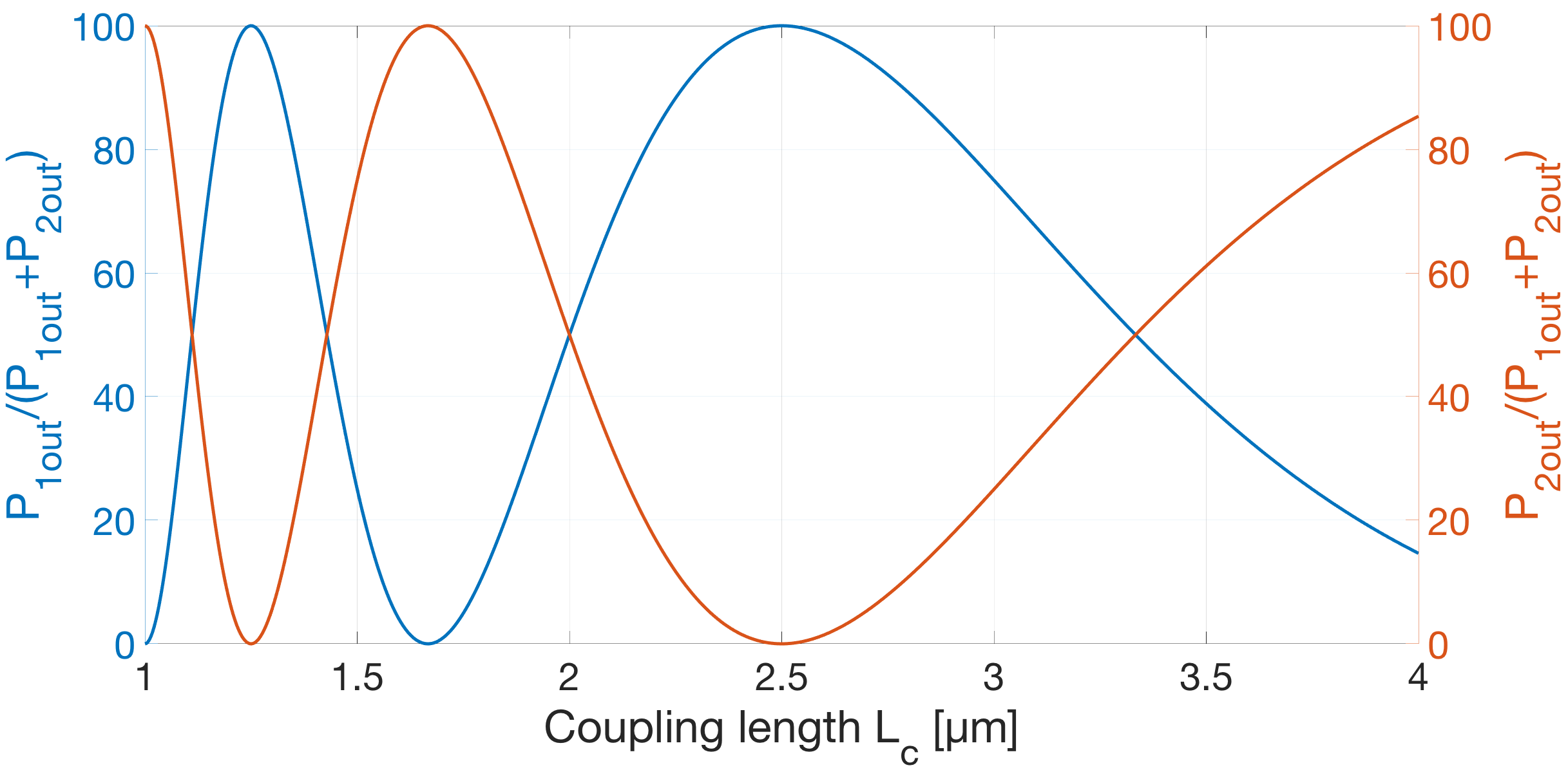
In CMOS-based electronics, the most straightforward way to implement a summation operation is to use the ripple carry adder (RCA). Magnonics, the field of science concerned with data processing by spin-waves and their quanta magnons, recently proposed a magnonic half-adder that can be considered as the simplest magnonic integrated circuit. Here, we develop a computation model for the magnonic basic blocks to enable the design and simulation of magnonic gates and magnonic circuits of arbitrary complexity and demonstrate its functionality on the example of a 32-bit integrated RCA. It is shown that the RCA requires the utilization of additional regenerators based on magnonic directional couplers with embedded amplifiers to normalize the magnon signals in-between the half-adders. The benchmarking of large-scale magnonic integrated circuits is performed. The energy consumption of 30 nm-based magnonic 32-bit adder can be as low as 961aJ per operation with taking into account all required amplifiers.
翻译:在以CMOS为基础的电子中,实施总和操作的最直接方式是使用波纹承载添加器(RCA)。磁力,即涉及通过旋波及其夸特巨猿进行数据处理的科学领域,最近提议了一个大型半添加器,可被视为简单的大音集集成电路。在这里,我们为大音基块开发了一个计算模型,以便能够设计和模拟具有任意复杂性的巨音门和巨声电路,并以32位集成RCA为例,展示其功能。显示RCA需要利用更多基于大音导向对齐机的再生成器,并配有嵌入式放大器,使半增殖器之间的大型声信号正常化。大型大型巨音集集集电路的基准已经实现。30纳米基大型32位巨音32位加热器的能量消耗量可以低至每运行961J,同时考虑所有需要的放大器。