机器翻译 | Bleu:此蓝;非彼蓝
作者:黑龙江大学nlp实验室本科生甄冉冉
阅读大概需要5分钟!
像seq2seq这样的模型,输入一个序列,输出一个序列,它的评分不像文本分类那样仅仅通过label是否一样来判断算出得分。比如机器翻译,它既要考虑语义,还要考虑语序。所以,在2002年一位国外的大牛(是的,没错基本木有中国人。。)Papineni et.al. 提出了Bleu方法,在Bleu:A method for automatic evaluation of machine translation中。
Bleu维基百科:BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
简单理解就是评价机器翻译的一个标准算法,但是Bleu也不仅仅局限于机器翻译,在文本摘要等应用也可以有同样的作用。
举个例子:

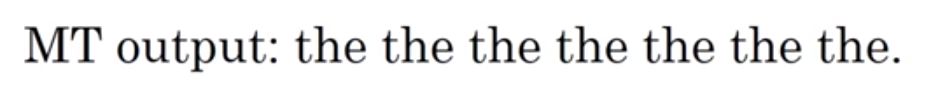
第一句是法语,需要把它翻译成英语;下面两个Reference句子是标准答案的参考(下面告诉你这个怎么用),最后一句就是机器翻译的句子。(举这个特例例子是也是因为会感受到机器学习评价算法的不断优化过程)
首先从一开始的Precision精确度说起:
Precision:就是看机器翻译的句子里的一个一个单词是不是在Reference中出现过,出现的话分子加1,其中该句子的长度值为分母,其实也就是计算该句子的出现的词在已给答案中出现的概率,这个很明显是7/7=1
但是,很明显这个方法是不合理的,比如在Reference中出现过一次的词就不能再参与计数了。随后,为了提出更加完善的方法,有人提出了modified recision 翻译为“修正的精确度”。
modified recision 还以这个为例:
其中设count为机器翻译的句子的词在本句子中出现的词数,count_clip为该句子中的词在Reference中对应的词出现的词数(如果两个都有,则选取最大的)评分为count_clip / count
现在我匹配 the,其中Reference1的the个数为2大于Reference2的the个数1,则the这个词的就选取值最大的Reference,即count_clip=2。因为这个句子就这一个词,count=7所以,评分为2/7。
上述可以说在unigram上,也就是一个词一个词,现在来说说Bleu在bigram上的计算:

bigram就是两个词作为一个大词(也就是一个串),这里为:

这个也很明显,结果为:

所以评分为:4/6
像这样,我们能推出n-gram的评分值为:
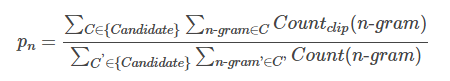
其中Candidate就是机器翻译出来的句子,即候选句子的意思。
很明显,如果一个机器翻译出来的句子和答案一样,那么它的P1,P2,。。。Pn都会为1.0。但是我们一般不会把n设为该句子的长度,根据前辈和论文中经常用到的值,我们得出P4是最合适的。也就是到4-gram就可以了。
但是想想为什么要用到n-gram呢?我觉得是这样的:
P1,也就是用unigram计算句子的词的精确度,用Pn,n>1的ngram来计算句子的流畅度!
现在我们来说另一个问题:
因为我们要把P1-4都要用起来,一起来评价,最好merge到一起,用一个值来表示。但是怎么merge到一起呢?大牛们说了:
merge到一起就该想到万能的一个数:e
对,就是这样(大牛们具体是这么做的):
首先将他们取和在平均(以n=4为例):
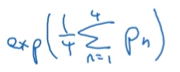
然后在乘一个值BP brevity penalty 目的是为了对短句子的惩罚:

大结局:
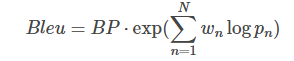
其中 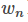
ok,就这样吧。如果有疑问,欢迎提出来,我们一起探讨!!

参考资料:
一种机器翻译的评价准则—Bleu
http://blog.csdn.net/qq_21190081/article/details/53115580
Andrew课程
以上图片来自于以上两种资料






