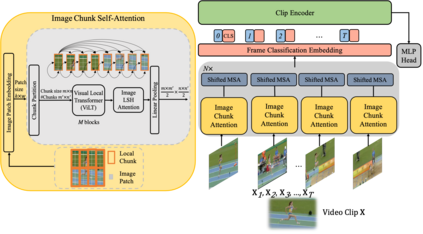
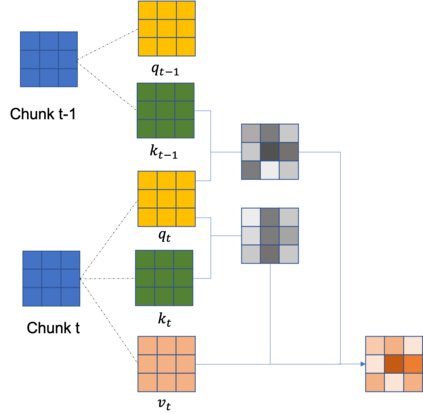
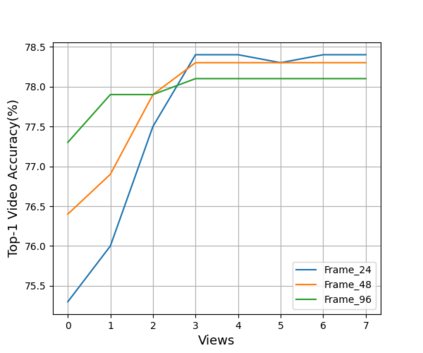
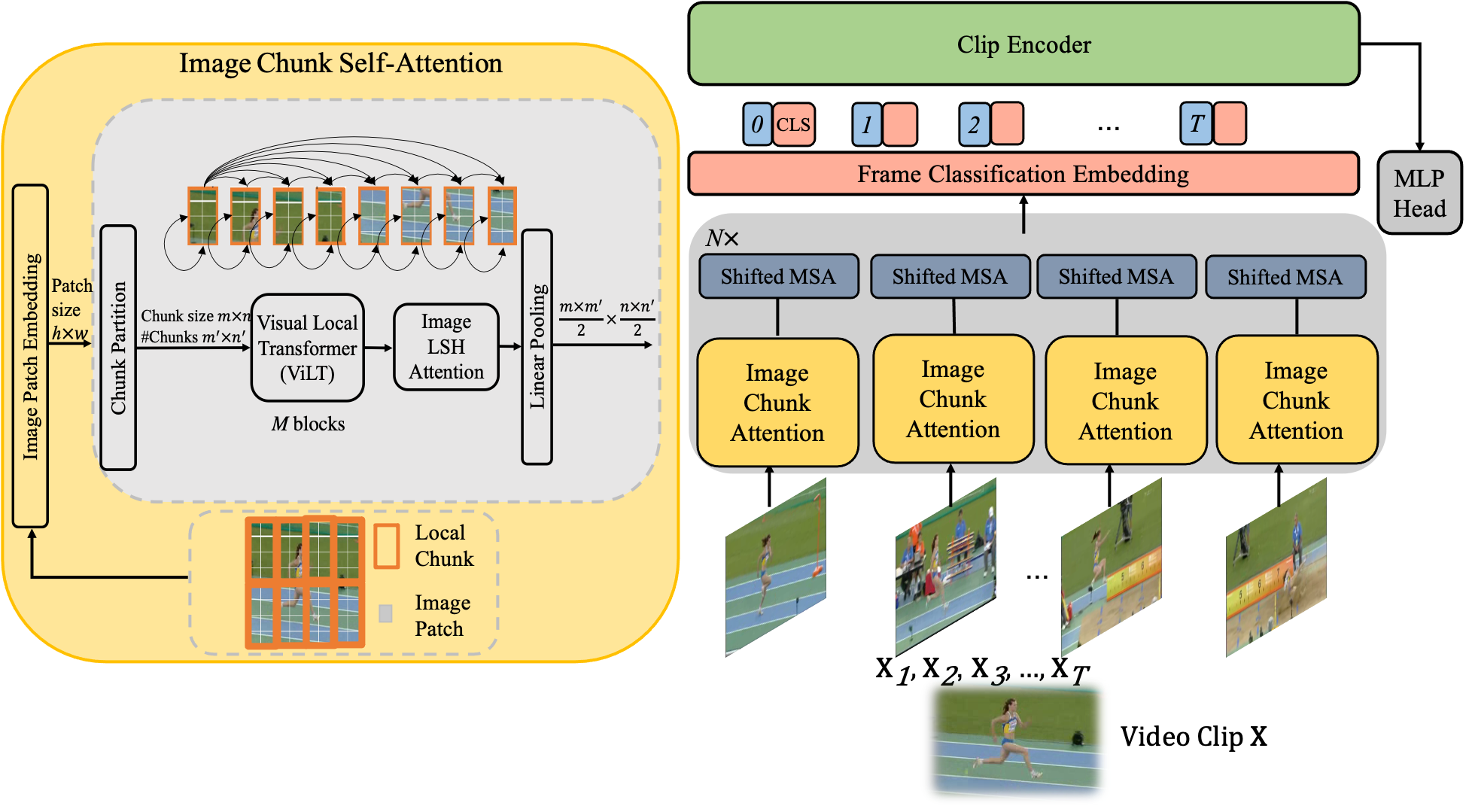
Spatio-temporal representational learning has been widely adopted in various fields such as action recognition, video object segmentation, and action anticipation. Previous spatio-temporal representational learning approaches primarily employ ConvNets or sequential models,e.g., LSTM, to learn the intra-frame and inter-frame features. Recently, Transformer models have successfully dominated the study of natural language processing (NLP), image classification, etc. However, the pure-Transformer based spatio-temporal learning can be prohibitively costly on memory and computation to extract fine-grained features from a tiny patch. To tackle the training difficulty and enhance the spatio-temporal learning, we construct a shifted chunk Transformer with pure self-attention blocks. Leveraging the recent efficient Transformer design in NLP, this shifted chunk Transformer can learn hierarchical spatio-temporal features from a local tiny patch to a global video clip. Our shifted self-attention can also effectively model complicated inter-frame variances. Furthermore, we build a clip encoder based on Transformer to model long-term temporal dependencies. We conduct thorough ablation studies to validate each component and hyper-parameters in our shifted chunk Transformer, and it outperforms previous state-of-the-art approaches on Kinetics-400, Kinetics-600, UCF101, and HMDB51.
翻译:在行动识别、视频对象分割和预期行动等各个领域广泛采用时空代表学习。以前的时空代表学习方法主要采用ConvNets或顺序模型,例如LSTM,以学习框架内和框架间特点。最近,变形模型成功地主导了自然语言处理(NLP)、图像分类等研究。然而,纯半透明基于600的时空空间学习对记忆和计算从一个小补丁中提取精细的成份成本过高。为了解决培训困难,加强时空学习,我们用纯自省块构建一个变形块变形器。利用NLP最近的高效变形器设计,这种变形模型可以学习从一个本地小补丁到一个全球视频剪接的上层-时空特征。我们变形的自我学习也可以有效地模拟复杂的跨框架差异。此外,我们用变形机、101和变形的硬基质模型构建了一个剪接器,我们每个变形的变形模型和变形的时空基础,我们每个变型的时空的时空基础,在以往的时空基础上都进行。