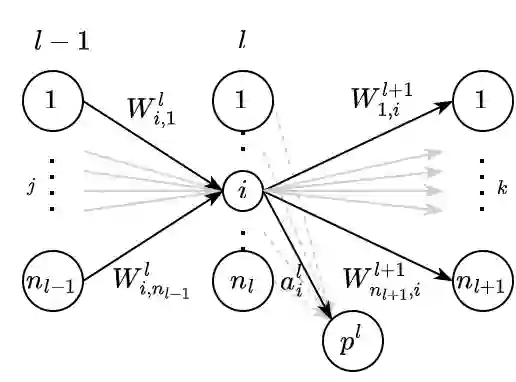
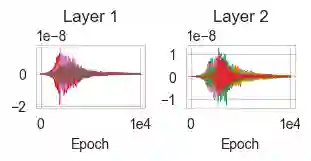
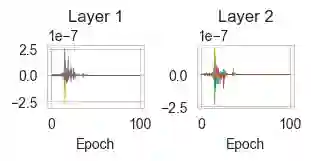
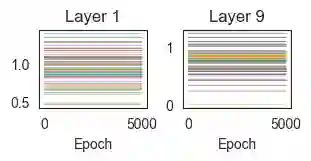
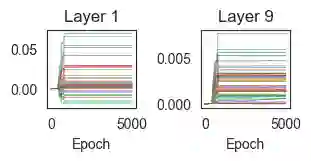
While the expressive power and computational capabilities of graph neural networks (GNNs) have been theoretically studied, their optimization and learning dynamics, in general, remain largely unexplored. Our study undertakes the Graph Attention Network (GAT), a popular GNN architecture in which a node's neighborhood aggregation is weighted by parameterized attention coefficients. We derive a conservation law of GAT gradient flow dynamics, which explains why a high portion of parameters in GATs with standard initialization struggle to change during training. This effect is amplified in deeper GATs, which perform significantly worse than their shallow counterparts. To alleviate this problem, we devise an initialization scheme that balances the GAT network. Our approach i) allows more effective propagation of gradients and in turn enables trainability of deeper networks, and ii) attains a considerable speedup in training and convergence time in comparison to the standard initialization. Our main theorem serves as a stepping stone to studying the learning dynamics of positive homogeneous models with attention mechanisms.
翻译:暂无翻译