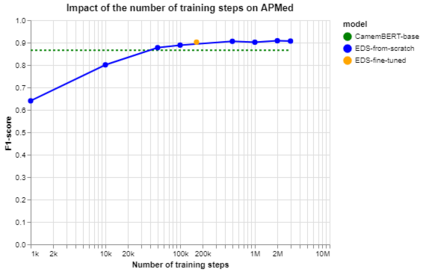
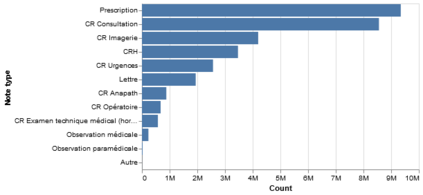
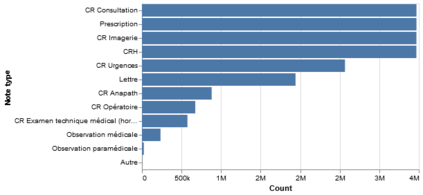
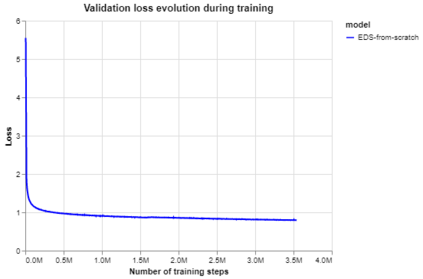
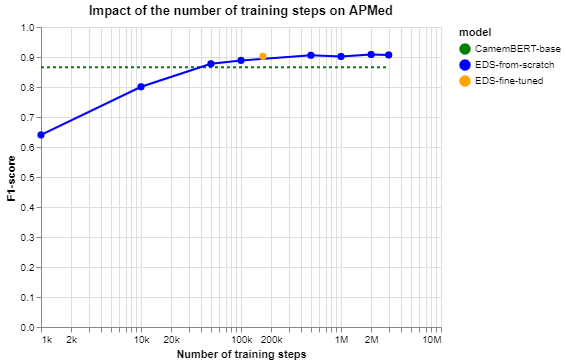
Background Clinical studies using real-world data may benefit from exploiting clinical reports, a particularly rich albeit unstructured medium. To that end, natural language processing can extract relevant information. Methods based on transfer learning using pre-trained language models have achieved state-of-the-art results in most NLP applications; however, publicly available models lack exposure to speciality-languages, especially in the medical field. Objective We aimed to evaluate the impact of adapting a language model to French clinical reports on downstream medical NLP tasks. Methods We leveraged a corpus of 21M clinical reports collected from August 2017 to July 2021 at the Greater Paris University Hospitals (APHP) to produce two CamemBERT architectures on speciality language: one retrained from scratch and the other using CamemBERT as its initialisation. We used two French annotated medical datasets to compare our language models to the original CamemBERT network, evaluating the statistical significance of improvement with the Wilcoxon test. Results Our models pretrained on clinical reports increased the average F1-score on APMed (an APHP-specific task) by 3 percentage points to 91%, a statistically significant improvement. They also achieved performance comparable to the original CamemBERT on QUAERO. These results hold true for the fine-tuned and from-scratch versions alike, starting from very few pre-training samples. Conclusions We confirm previous literature showing that adapting generalist pre-train language models such as CamenBERT on speciality corpora improves their performance for downstream clinical NLP tasks. Our results suggest that retraining from scratch does not induce a statistically significant performance gain compared to fine-tuning.
翻译:使用现实世界数据的背景临床研究可能受益于利用临床报告,这是一个特别丰富但非结构化的媒介。为此,自然语言处理可以提取相关信息。基于培训前语言模型的转让学习方法,在大多数NLP应用中取得了最新成果;然而,公开使用的模式缺乏特殊语言,特别是在医疗领域。我们的目的是评估将语言模型改用法国下游医学NLP任务临床报告的影响。我们利用了2017年8月至2021年7月在大巴黎大学医院(APHP)收集的21M临床报告,以生成两个特殊语言的CamembERT结构:一个从零开始重新训练,另一个在初始化时使用CamembERT。我们用两个法文附加说明的医疗数据集来比较我们的语言模型与原CamemBERT网络,评估改进与Wilcoxon少数测试的统计意义。我们在临床报告中提前增加了AMPM(APH特定特殊任务)的平均F1级临床报告,从最初的Servicialalality 开始将业绩提升为91 %。我们从统计前的升级前的统计结果也显示了我们先前的成绩。我们以前的Serverealal-ral-ralal的改进了我们从最初的成绩,从最初的PB的改进到实际的成绩。我们从最初的改进为91。