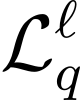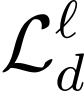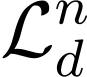Automatic Speech Recognition (ASR) systems, despite large multilingual training, struggle in out-of-domain and low-resource scenarios where labeled data is scarce. We propose BEARD (BEST-RQ Encoder Adaptation with Re-training and Distillation), a novel framework designed to adapt Whisper's encoder using unlabeled data. Unlike traditional self-supervised learning methods, BEARD uniquely combines a BEST-RQ objective with knowledge distillation from a frozen teacher encoder, ensuring the encoder's complementarity with the pre-trained decoder. Our experiments focus on the ATCO2 corpus from the challenging Air Traffic Control (ATC) communications domain, characterized by non-native speech, noise, and specialized phraseology. Using about 5,000 hours of untranscribed speech for BEARD and 2 hours of transcribed speech for fine-tuning, the proposed approach significantly outperforms previous baseline and fine-tuned model, achieving a relative improvement of 12% compared to the fine-tuned model. To the best of our knowledge, this is the first work to use a self-supervised learning objective for domain adaptation of Whisper.
翻译:暂无翻译