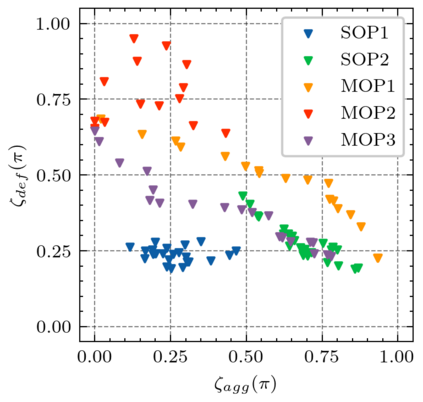
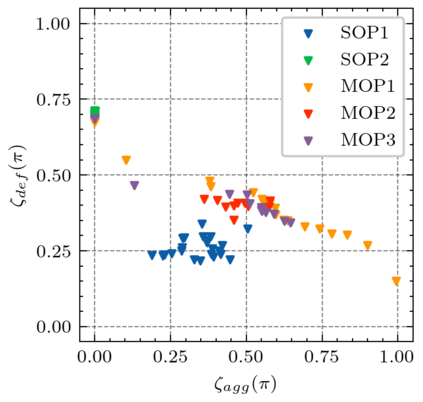
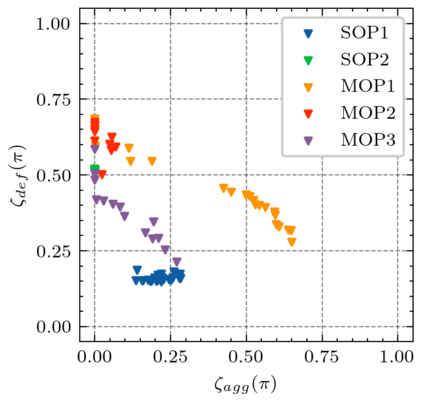
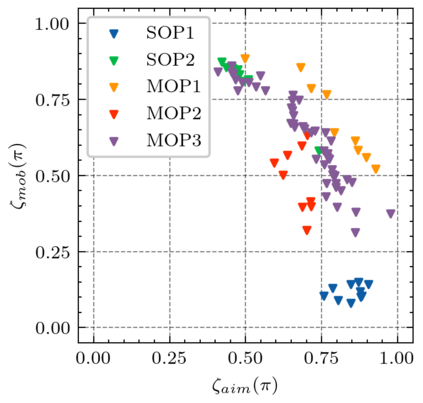
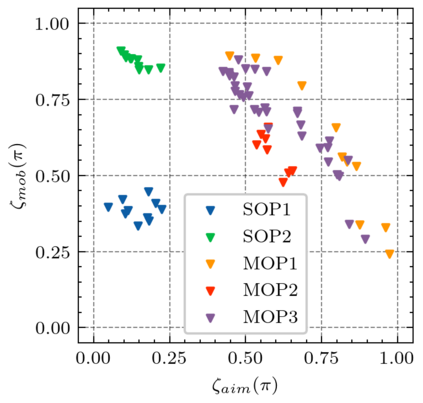
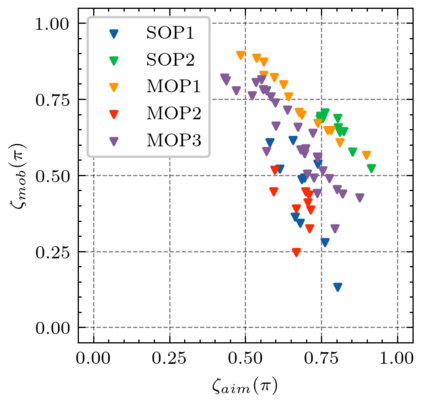
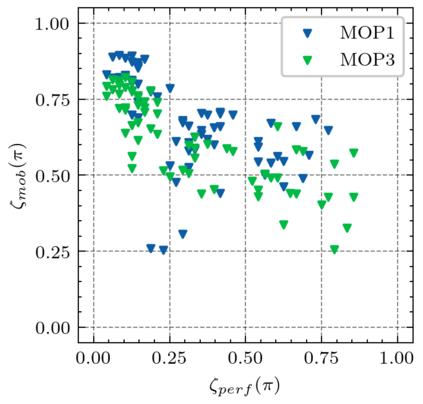
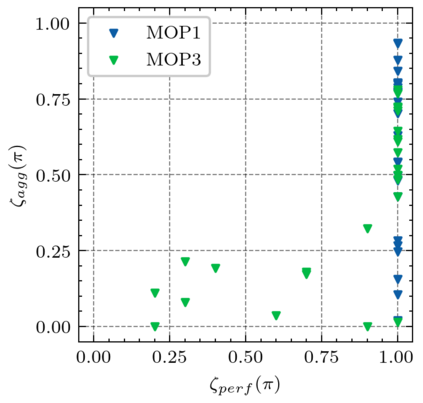
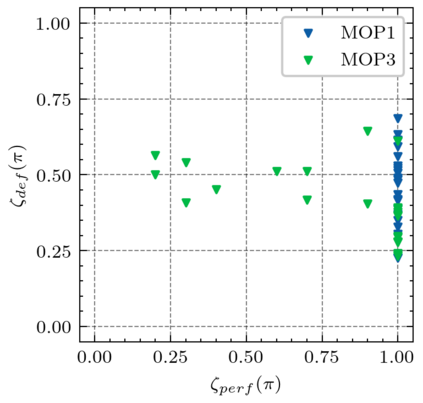
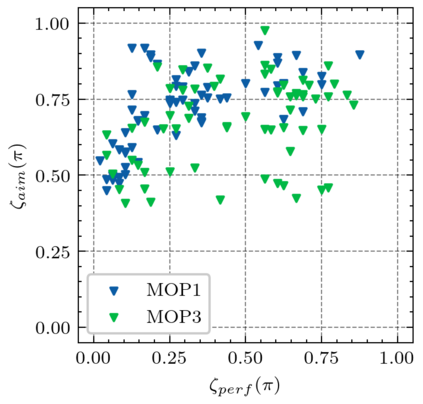
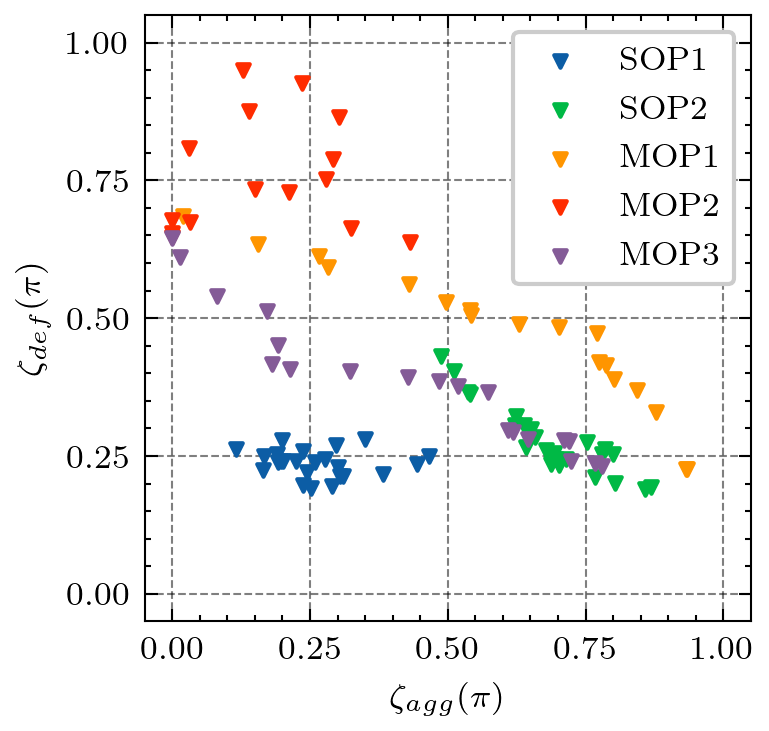
Generating various strategies for a given task is challenging. However, it has already proven to bring many assets to the main learning process, such as improved behavior exploration. With the growth in the interest of heterogeneity in solution in evolutionary computation and reinforcement learning, many promising approaches have emerged. To better understand how one guides multiple policies toward distinct strategies and benefit from diversity, we need to analyze further the influence of the reward signal modulation and other evolutionary mechanisms on the obtained behaviors. To that effect, this paper considers an existing evolutionary reinforcement learning framework which exploits multi-objective optimization as a way to obtain policies that succeed at behavior-related tasks as well as completing the main goal. Experiments on the Atari games stress that optimization formulations which do not consider objectives equally fail at generating diversity and even output agents that are worse at solving the problem at hand, regardless of the obtained behaviors.
翻译:为某一特定任务制定各种战略是具有挑战性的。然而,已经证明它将许多资产引入了主要学习过程,例如改进行为探索。随着在进化计算和强化学习中解决方案的异质性增长,出现了许多有希望的方法。为了更好地了解如何指导多重政策走向不同的战略和从多样性中受益,我们需要进一步分析奖励信号调节和其他演化机制对所获行为的影响。为此,本文件审议了现有的演进强化学习框架,该框架利用多目标优化作为获取成功完成与行为有关的任务以及完成主要目标的政策的一种途径。对阿塔里游戏的实验强调,不认为目标在产生多样性甚至产出要素方面同样失败的优化配方,而这些在解决问题方面甚至更糟,而不论获得的行为如何。