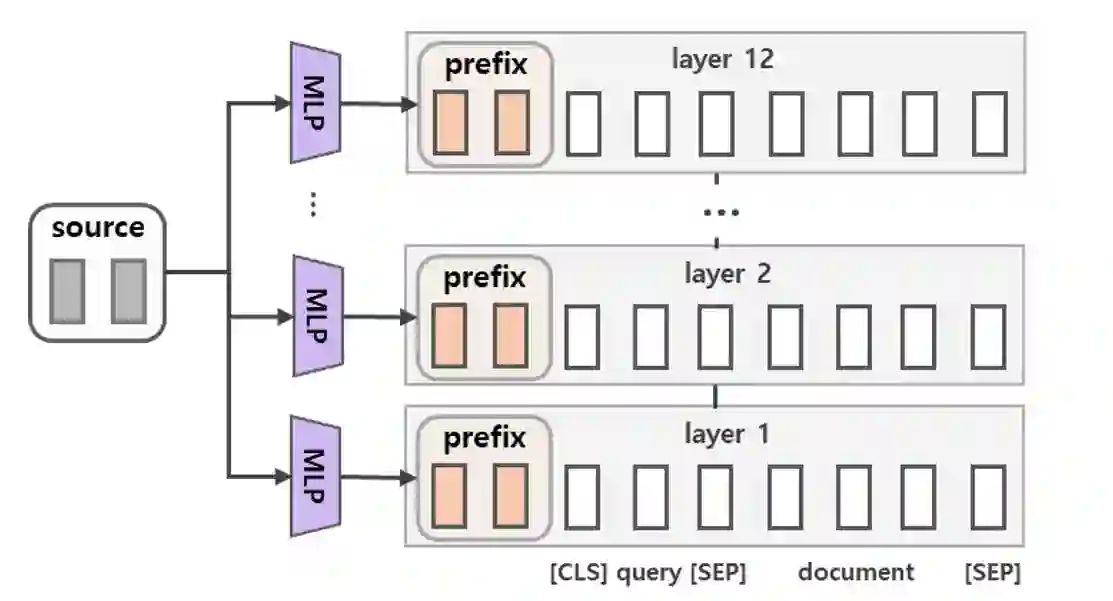
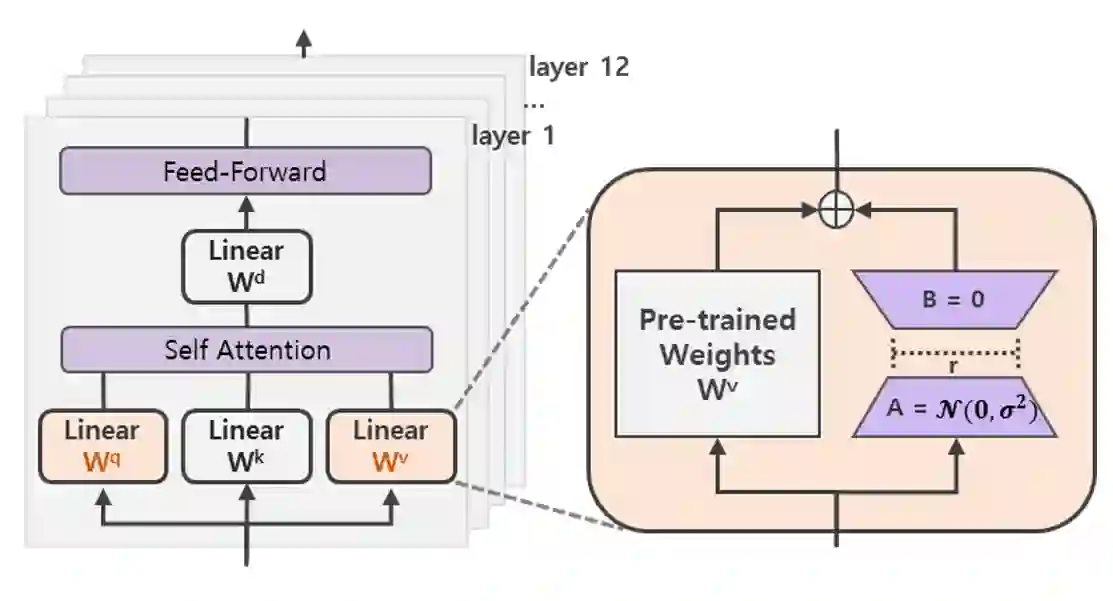
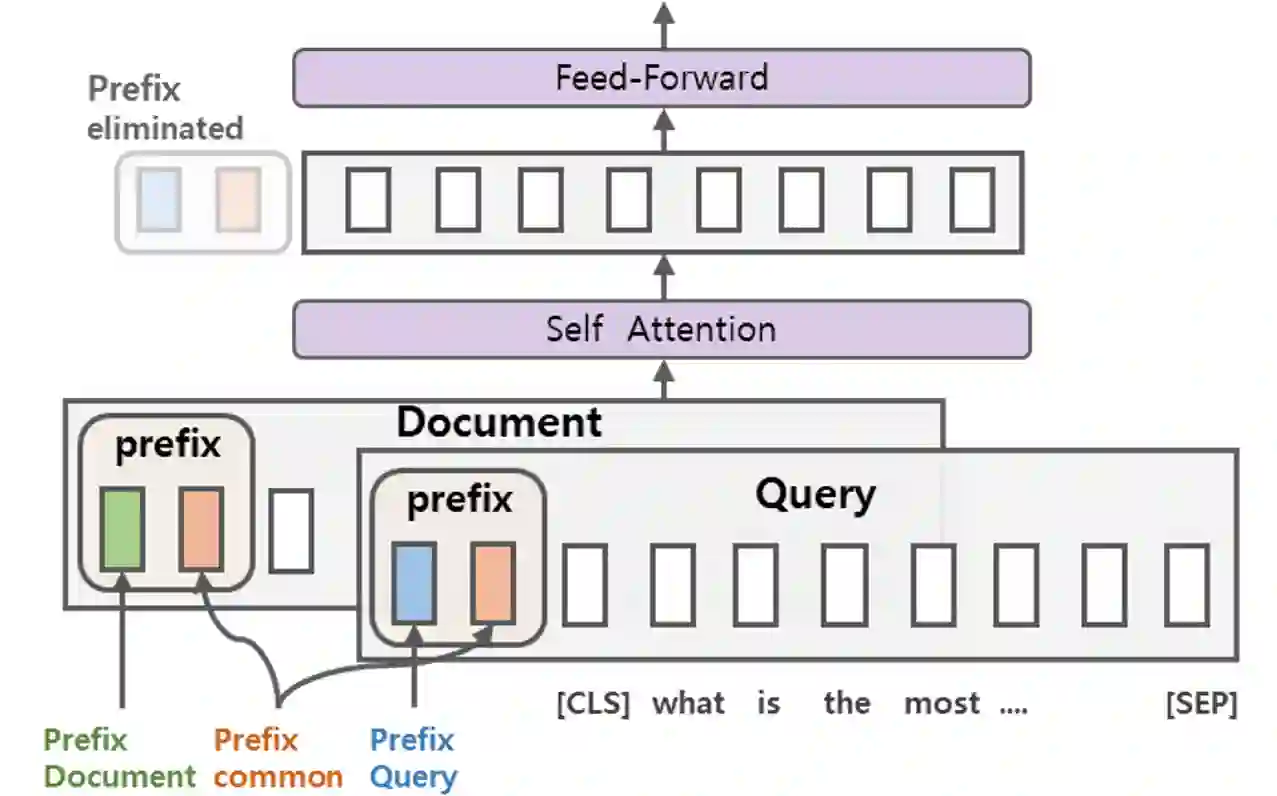
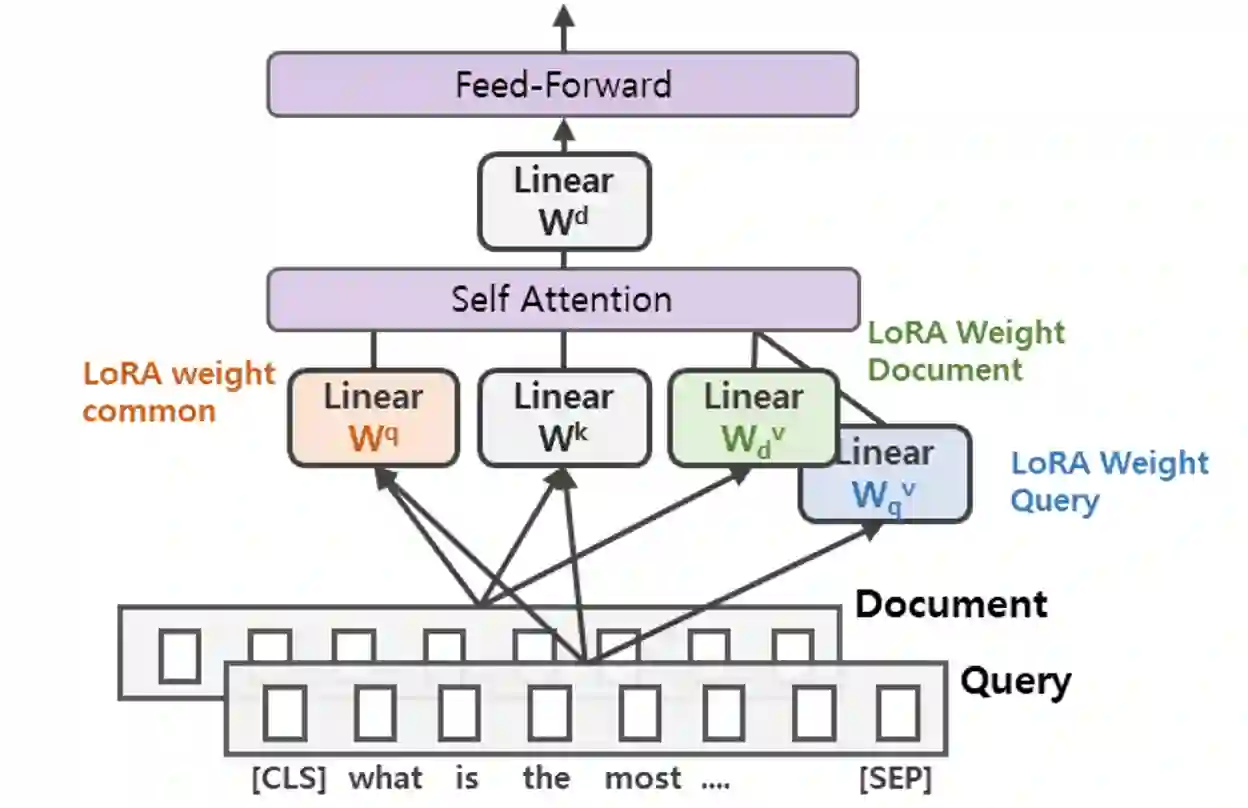
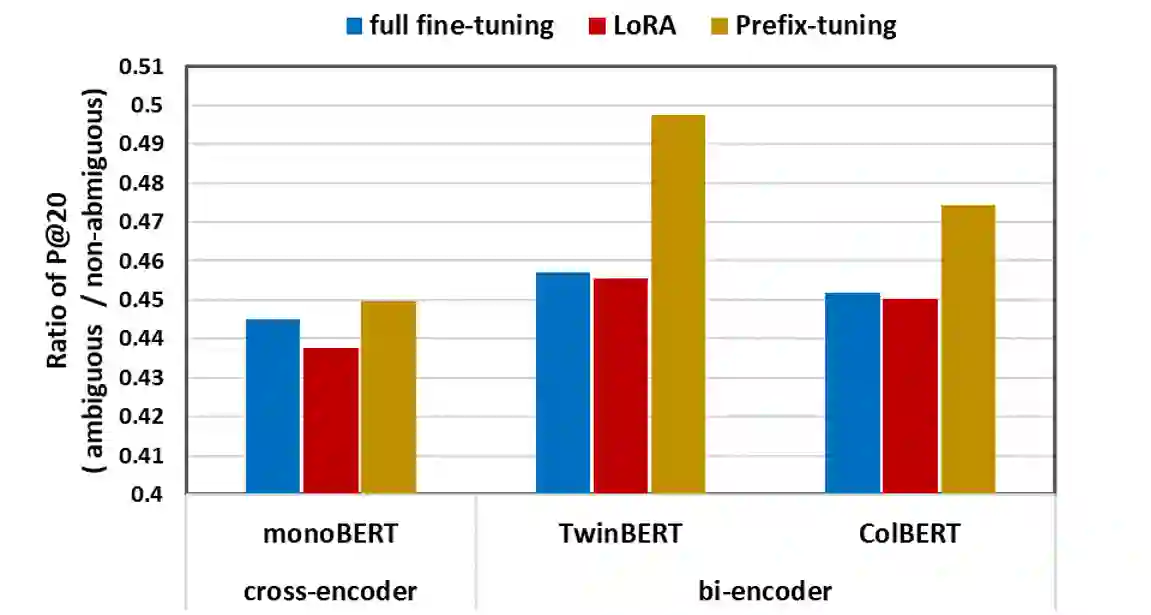
A BERT-based Neural Ranking Model (NRM) can be either a cross-encoder or a bi-encoder. Between the two, bi-encoder is highly efficient because all the documents can be pre-processed before the actual query time. Although query and document are independently encoded, the existing bi-encoder NRMs are Siamese models where a single language model is used for consistently encoding both of query and document. In this work, we show two approaches for improving the performance of BERT-based bi-encoders. The first approach is to replace the full fine-tuning step with a lightweight fine-tuning. We examine lightweight fine-tuning methods that are adapter-based, prompt-based, and hybrid of the two. The second approach is to develop semi-Siamese models where queries and documents are handled with a limited amount of difference. The limited difference is realized by learning two lightweight fine-tuning modules, where the main language model of BERT is kept common for both query and document. We provide extensive experiment results for monoBERT, TwinBERT, and ColBERT where three performance metrics are evaluated over Robust04, ClueWeb09b, and MS-MARCO datasets. The results confirm that both lightweight fine-tuning and semi-Siamese are considerably helpful for improving BERT-based bi-encoders. In fact, lightweight fine-tuning is helpful for cross-encoder, too.
翻译:以BERT为基础的神经分级模型(NRM)可以是跨级编码器,也可以是双编码器。在两种方法之间,双编码器非常高效,因为所有文件都可以在实际查询时间之前预处理。虽然查询和文件是独立编码的,但现有的双编码码NRM是Siame模型,其中使用单一语言模型对查询和文件进行一致编码。在这项工作中,我们展示了两种改进基于BERT的有益双编码器业绩的方法。第一个方法是用轻度微调取代整个微调步骤。我们检查了所有文件在实际查询时间之前的预处理。虽然查询和文件是独立编码的,但现有的双编码NRMRM(双码)是Siame模型,其中使用一种单一语言模型对查询和文件进行一致编码。我们提供了两种轻度微调模块,其中BERT的主要语言模型对查询和文件都是常见的。我们为 SIBERT、SUBERT和CROBER(B-B-BER)提供了广泛的试验结果结果结果,其中三度数据是B-B-B-B-B-C-C-S-BS-B-B-C-C-C-C-C-C-C-C-C-SUDRD-S-ID-ID-ID-S-S-S-S-S-S-S-S-D-ID-D-D-D-D-D-D-D-D-BD-BD-BD-C-D-D-C-D-D-D-D-BD-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-BD-D-D-C-BD-BD-D-D-C-D-C-C-C-C-C-C-C-C-BD-D-SD-BD-BD-D-D-D-D-D-S-S-S-B-B-B-S-B-B-B-D-D-D-BD-D-C-D-D-D-D-D-D-D-B