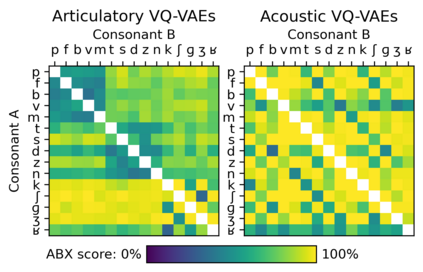
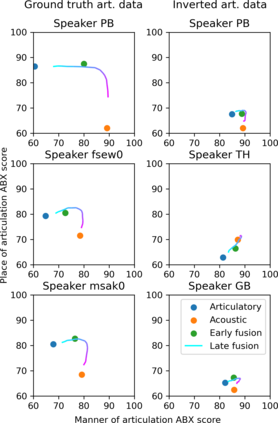
The human perception system is often assumed to recruit motor knowledge when processing auditory speech inputs. Using articulatory modeling and deep learning, this study examines how this articulatory information can be used for discovering speech units in a self-supervised setting. We used vector-quantized variational autoencoders (VQ-VAE) to learn discrete representations from articulatory and acoustic speech data. In line with the zero-resource paradigm, an ABX test was then used to investigate how the extracted representations encode phonetically relevant properties. Experiments were conducted on three different corpora in English and French. We found that articulatory information rather organises the latent representations in terms of place of articulation whereas the speech acoustics mainly structure the latent space in terms of manner of articulation. We show that an optimal fusion of the two modalities can lead to a joint representation of these phonetic dimensions more accurate than each modality considered individually. Since articulatory information is usually not available in a practical situation, we finally investigate the benefit it provides when inferred from the speech acoustics in a self-supervised manner.
翻译:人类感知系统通常被假定在处理听力语音输入时会征聘运动知识。本研究利用动脉模型和深层学习,研究如何利用这种动脉信息在自我监督的环境中发现语音单位。我们使用矢量定量的变异自动电解器(VQ-VAE)从动脉和声学语音数据中学习离散的表达方式。根据零资源模式,随后使用ABX测试来调查提取的表达方式如何将语音相关属性编码化。在英文和法文的三个不同的子公司进行了实验。我们发现,动脉信息更倾向于在表达位置上组织潜在表达方式,而语音声音主要是在表达方式上构建潜在空间。我们显示,两种模式的优化融合可以导致这些语音维度的联合表述比个别考虑的每一种模式更准确。由于在实际情况下通常无法获得动脉冲信息,我们最终调查了它从以自我控制的方式从语音声调中推断出的好处。