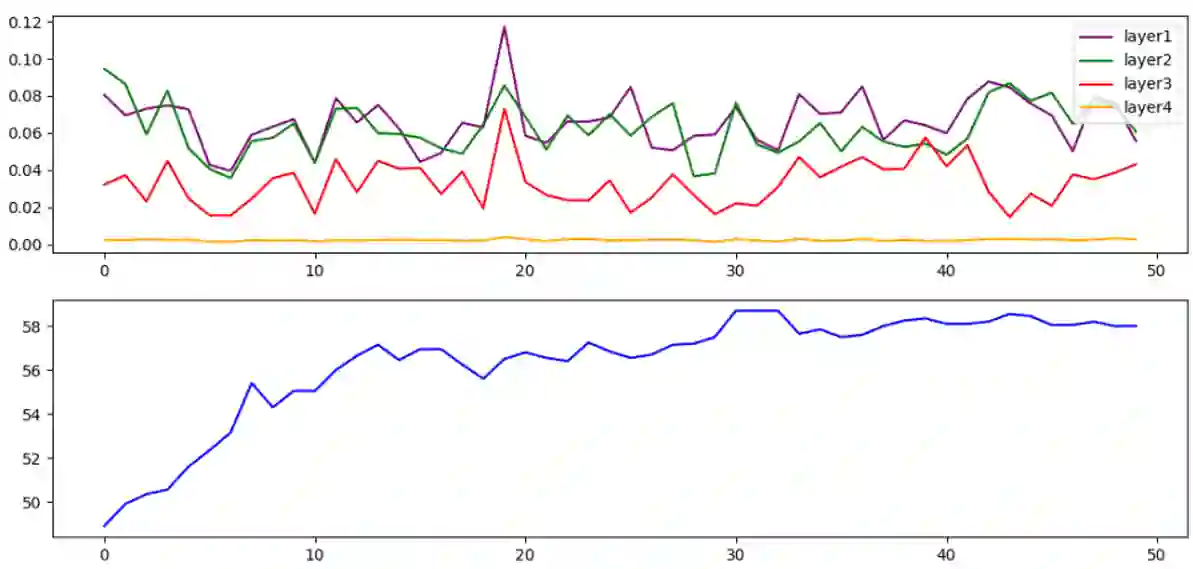
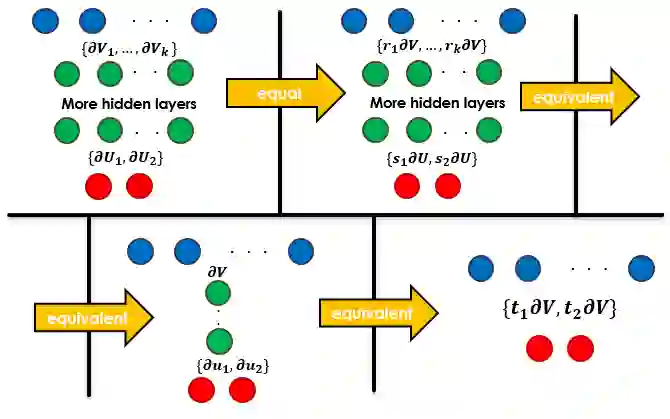
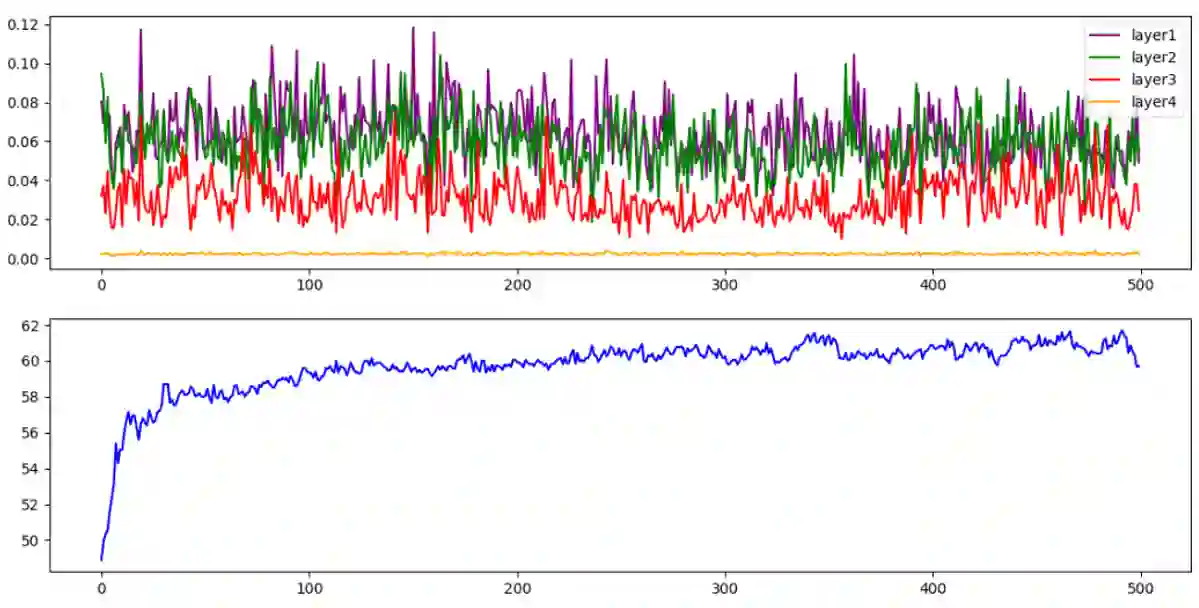
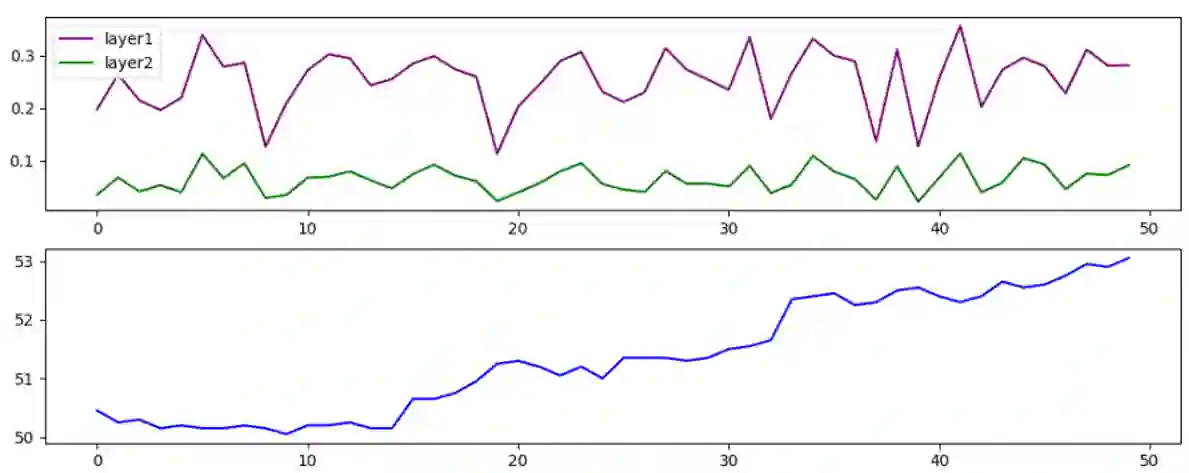
Conventional wisdom states that deep linear neural networks benefit from expressiveness and optimization advantages over a single linear layer. This paper suggests that, in practice, the training process of deep linear fully-connected networks using conventional optimizers is convex in the same manner as a single linear fully-connected layer. This paper aims to explain this claim and demonstrate it. Even though convolutional networks are not aligned with this description, this work aims to attain a new conceptual understanding of fully-connected linear networks that might shed light on the possible constraints of convolutional settings and non-linear architectures.
翻译:常规智慧指出,深海线性神经网络受益于单一线性层的表达性和优化优势。 本文指出,在实践中,使用常规优化器的深线性完全连接网络的培训过程与单一线性完全连接的层一样,是同单一线性完全连接的层一样的曲线。 本文旨在解释并展示这一说法。 尽管进化网络与这一描述不相符,但这项工作旨在对完全连接的线性网络取得新的概念性理解,从而可以揭示进化环境和非线性结构的可能制约因素。