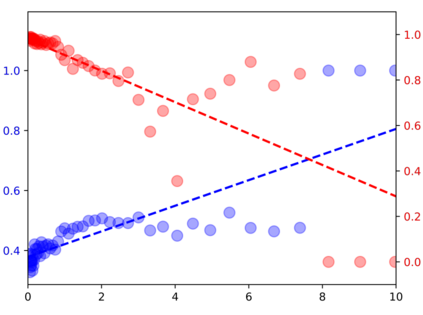
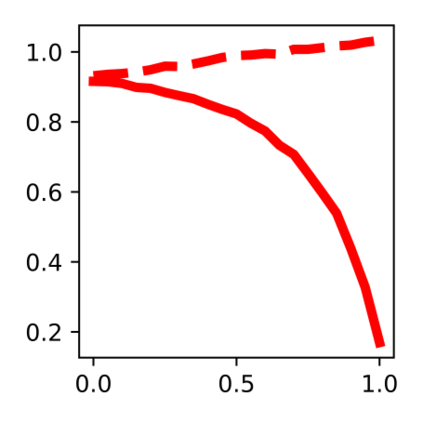
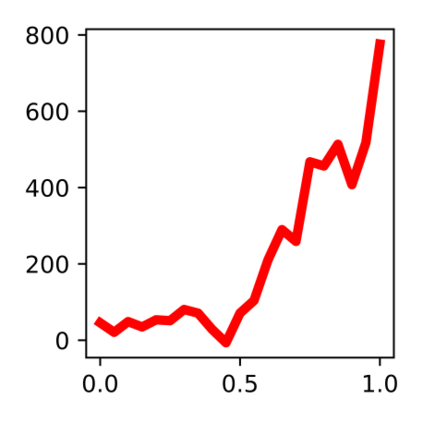
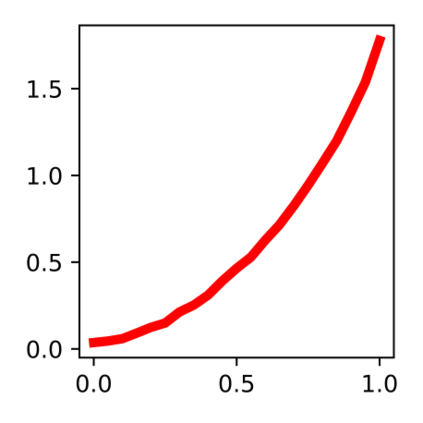
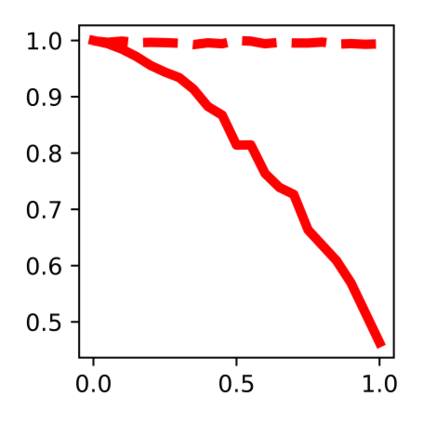
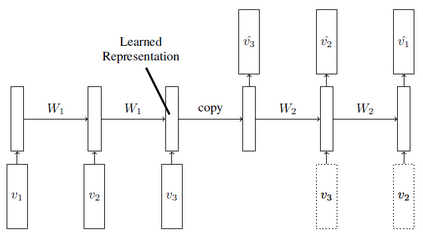
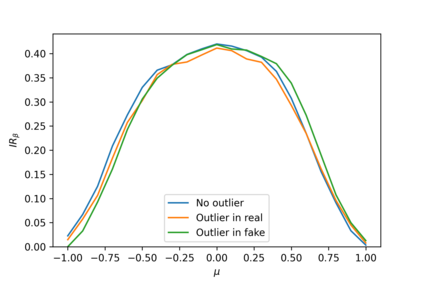
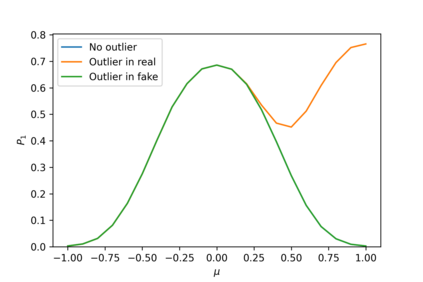
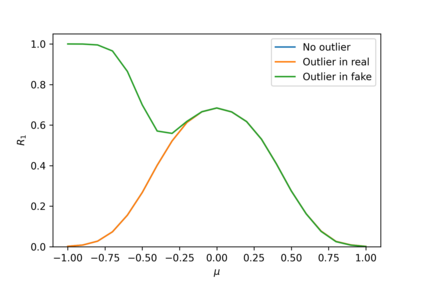
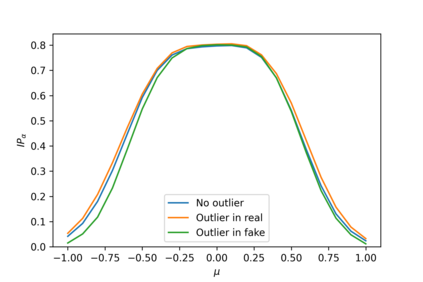
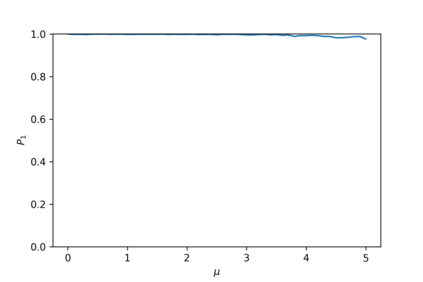
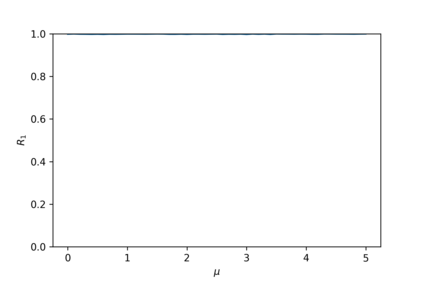
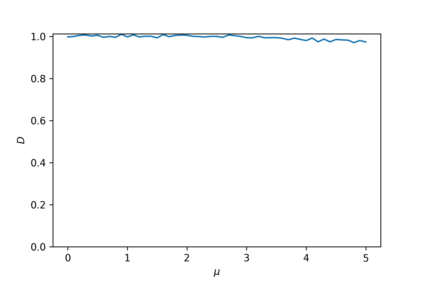
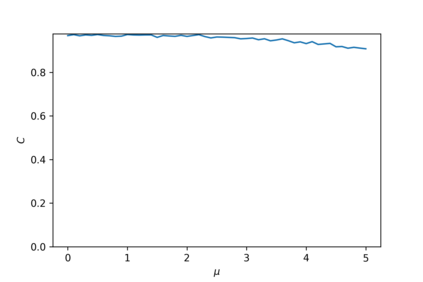
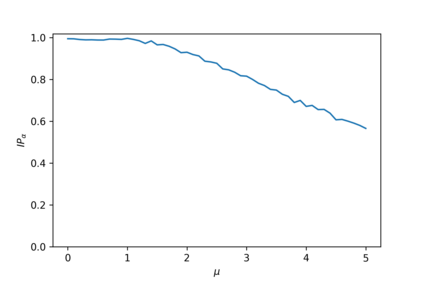
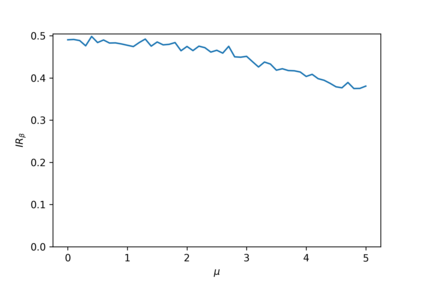
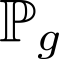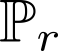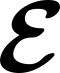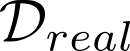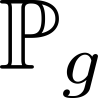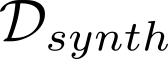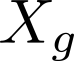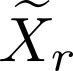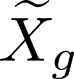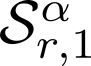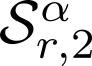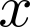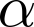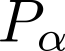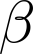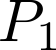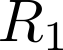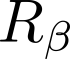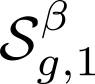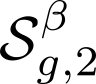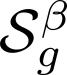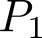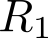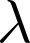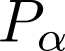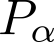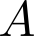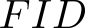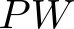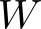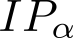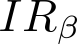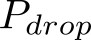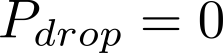Devising domain- and model-agnostic evaluation metrics for generative models is an important and as yet unresolved problem. Most existing metrics, which were tailored solely to the image synthesis setup, exhibit a limited capacity for diagnosing the different modes of failure of generative models across broader application domains. In this paper, we introduce a 3-dimensional evaluation metric, ($\alpha$-Precision, $\beta$-Recall, Authenticity), that characterizes the fidelity, diversity and generalization performance of any generative model in a domain-agnostic fashion. Our metric unifies statistical divergence measures with precision-recall analysis, enabling sample- and distribution-level diagnoses of model fidelity and diversity. We introduce generalization as an additional, independent dimension (to the fidelity-diversity trade-off) that quantifies the extent to which a model copies training data -- a crucial performance indicator when modeling sensitive data with requirements on privacy. The three metric components correspond to (interpretable) probabilistic quantities, and are estimated via sample-level binary classification. The sample-level nature of our metric inspires a novel use case which we call model auditing, wherein we judge the quality of individual samples generated by a (black-box) model, discarding low-quality samples and hence improving the overall model performance in a post-hoc manner.
翻译:为基因模型设计域名和模型名评价指标是一个重要和尚未解决的问题。大多数现有指标是专门为图像合成设置而设计的,在诊断更广泛的应用领域的基因模型不同失败模式方面能力有限。在本文中,我们引入了三维评价指标,即(alpha$-precision, $\beta$-Recall, $\beta$-Regeta-Recall, 真实性),这是任何基因模型在域名方式上的忠实性、多样性和通用性能的特点。我们用精确召回分析,使对模型忠实性和多样性的抽样和分布层次诊断成为统一的统计差异计量标准。我们引入了一般化作为额外、独立的层面(对忠诚多样性交易),以量化模型复制培训数据的程度 -- -- 在模拟具有模型隐私要求的敏感数据时,一个关键的业绩指标 -- -- 三个指标与(互换)比较性、可比较性数量相对,并通过抽样分级分类来估算。我们采用抽样级标准级标准级标准,我们采用了一个测试质量标准级的样本级标准,我们用一个测试标准级标准级的样本,从而检验了我们使用一个新的案例。