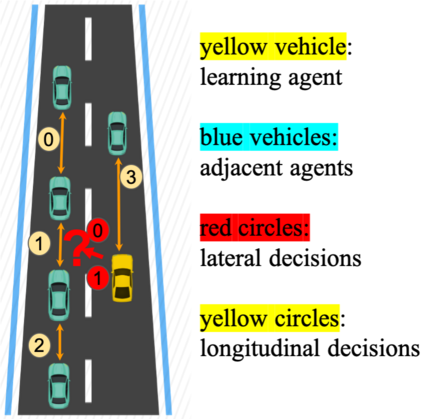
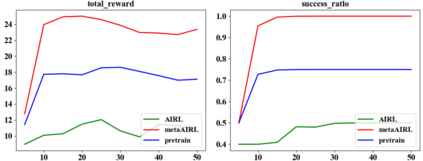
Learning from demonstrations has made great progress over the past few years. However, it is generally data hungry and task specific. In other words, it requires a large amount of data to train a decent model on a particular task, and the model often fails to generalize to new tasks that have a different distribution. In practice, demonstrations from new tasks will be continuously observed and the data might be unlabeled or only partially labeled. Therefore, it is desirable for the trained model to adapt to new tasks that have limited data samples available. In this work, we build an adaptable imitation learning model based on the integration of Meta-learning and Adversarial Inverse Reinforcement Learning (Meta-AIRL). We exploit the adversarial learning and inverse reinforcement learning mechanisms to learn policies and reward functions simultaneously from available training tasks and then adapt them to new tasks with the meta-learning framework. Simulation results show that the adapted policy trained with Meta-AIRL can effectively learn from limited number of demonstrations, and quickly reach the performance comparable to that of the experts on unseen tasks.
翻译:在过去几年里,从示范中学习的经验取得了很大进展,但一般而言,这是数据饥饿和任务特有的。换句话说,它需要大量的数据来训练一个适合特定任务的适当模式,而模型往往不能概括到具有不同分布的新任务。实际上,将不断观察新任务的示范,数据可能没有标签或只是部分标签。因此,受过训练的模式应该适应现有数据样本有限的新任务。在这项工作中,我们根据Meta-学习和Aversarial adversarial Inversal Enterement Learning(Meta-AIRL)的结合,建立一个适应性模仿学习模式。我们利用对抗性学习和反强化学习机制,从现有的培训任务中同时学习政策和奖励职能,然后根据元学习框架使其适应新的任务。模拟结果表明,经过Meta-AIRL培训的经调整的政策可以有效地从有限的示范中学习,并迅速达到与看不见任务专家相似的业绩。