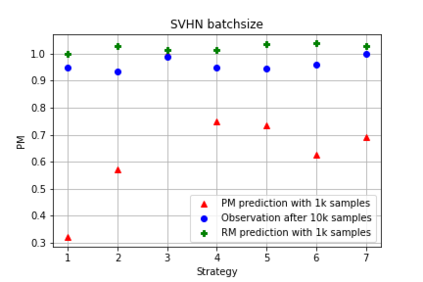
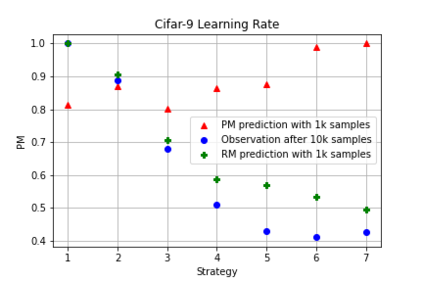
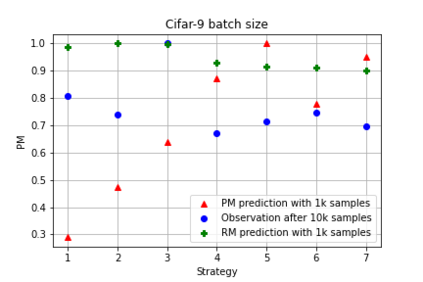
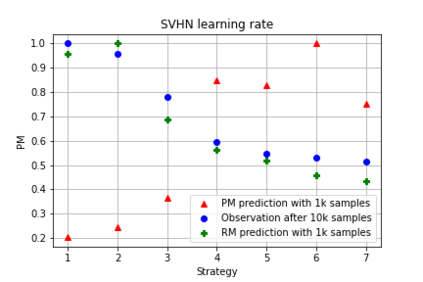
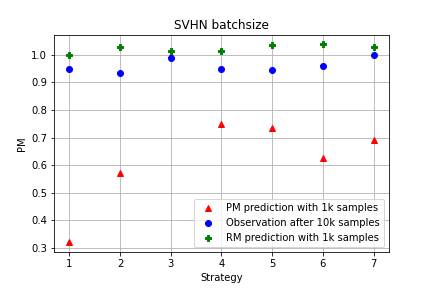
It is prevalent and well-observed, but poorly understood, that two machine learning models with similar performance during training can have very different real-world performance characteristics. This implies elusive differences in the internals of the models, manifesting as representational multiplicity (RM). We introduce a conceptual and experimental setup for analyzing RM and show that certain training methods systematically result in greater RM than others, measured by activation similarity via singular vector canonical correlation analysis (SVCCA). We further correlate it with predictive multiplicity measured by the variance in i.i.d. and out-of-distribution test set predictions, in four common image data sets. We call for systematic measurement and maximal exposure, not elimination, of RM in models. Qualitative tools such as our confabulator analysis can facilitate understanding and communication of RM effects to stakeholders.
翻译:培训期间业绩相似的两种机器学习模式可能具有非常不同的真实世界性业绩特征,这意味着这些模式的内部差异难以捉摸,表现为代表多样性(RM)。 我们引入了分析RM的概念和实验性设置,并表明某些培训方法系统地产生比其他人更大的RM,通过单一矢量和传导相关分析(SVCCA)激活相似性来衡量。我们进一步将它与根据i.d.的差异衡量的预测多样性以及四个通用图像数据集的分发外测试所设定的预测联系起来。我们呼吁在模型中系统测量和最大限度地接触(而不是消除)RM。我们的调控器分析等定性工具可以促进了解和向利益攸关方通报RM效应。