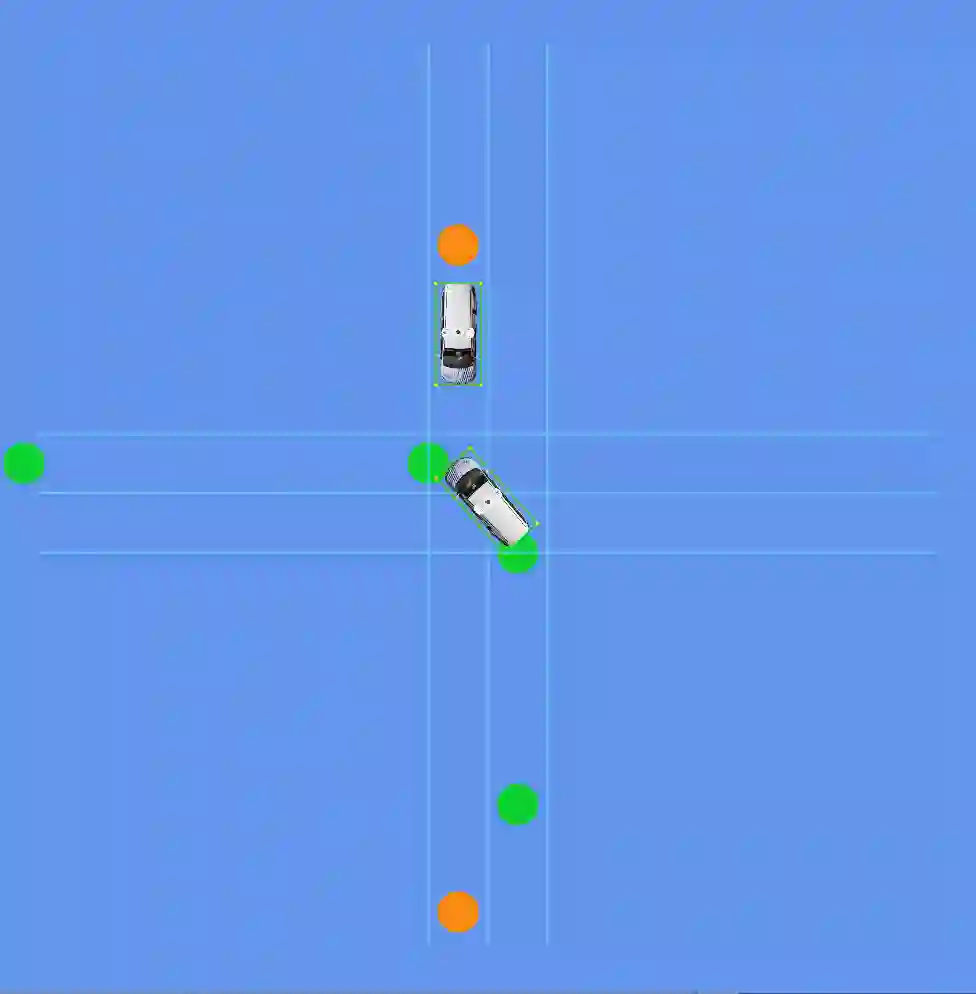
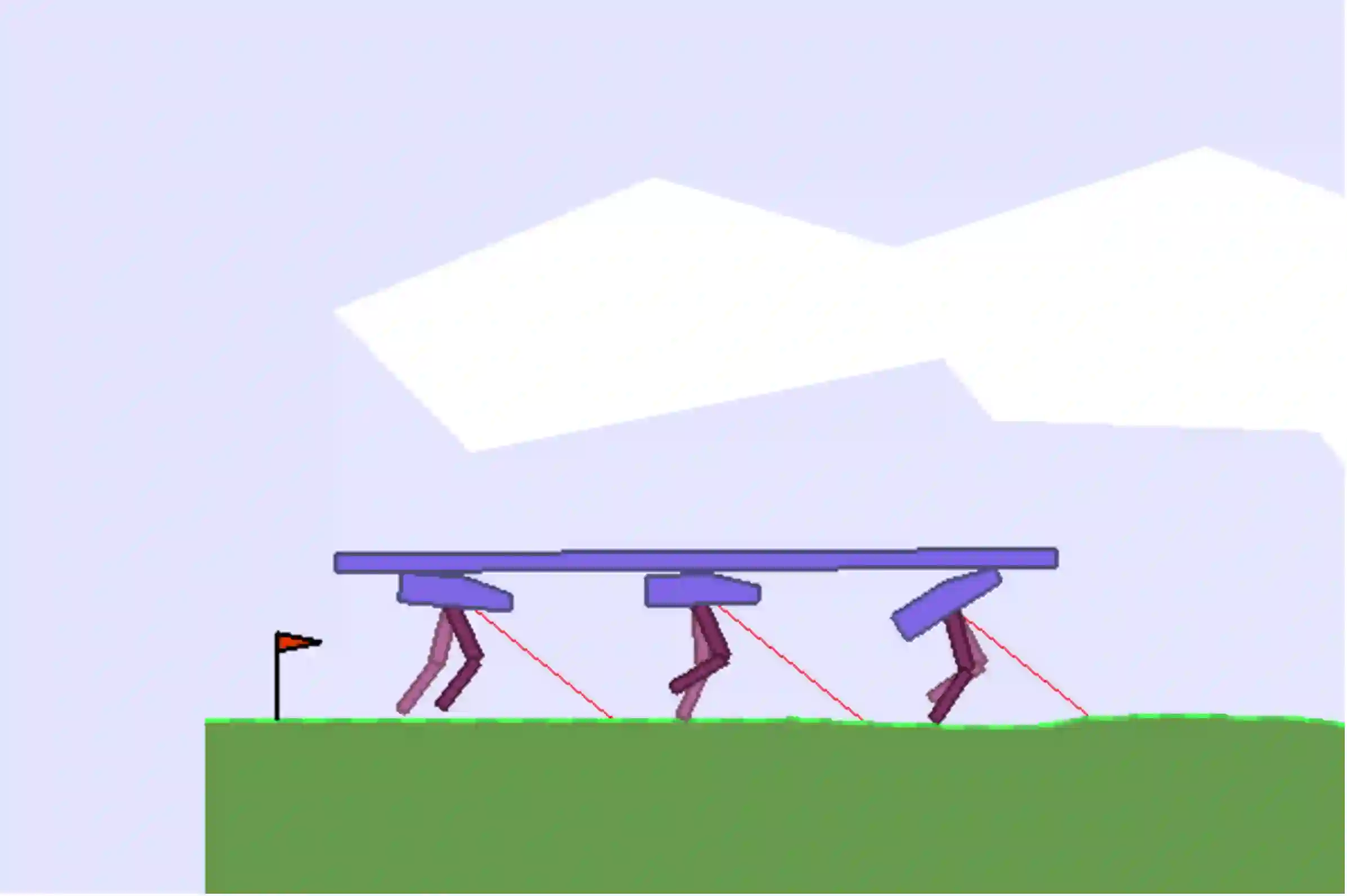
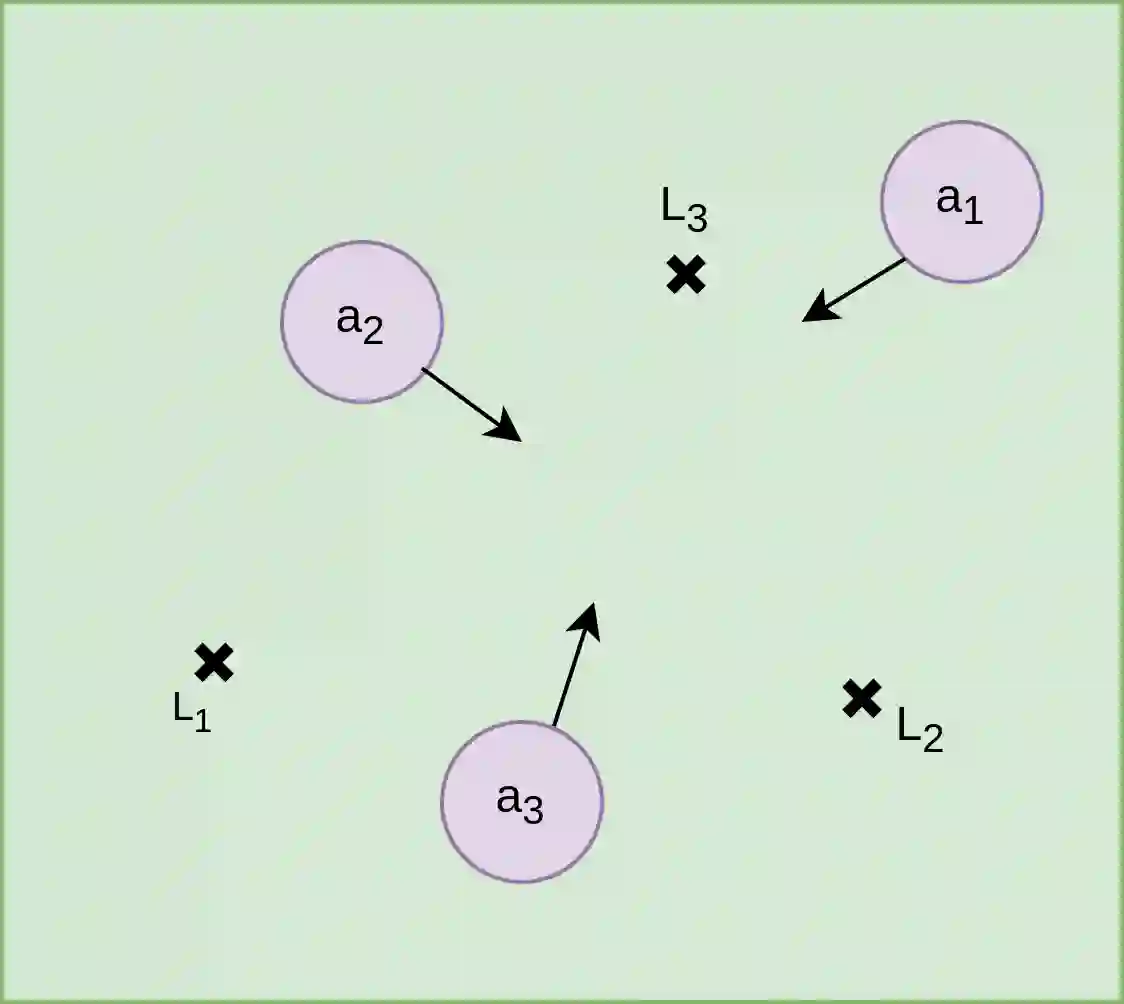
This work considers the problem of learning cooperative policies in multi-agent settings with partially observable and non-stationary environments without a communication channel. We focus on improving information sharing between agents and propose a new multi-agent actor-critic method called \textit{Multi-Agent Cooperative Recurrent Proximal Policy Optimization} (MACRPO). We propose two novel ways of integrating information across agents and time in MACRPO: First, we use a recurrent layer in critic's network architecture and propose a new framework to use a meta-trajectory to train the recurrent layer. This allows the network to learn the cooperation and dynamics of interactions between agents, and also handle partial observability. Second, we propose a new advantage function that incorporates other agents' rewards and value functions. We evaluate our algorithm on three challenging multi-agent environments with continuous and discrete action spaces, Deepdrive-Zero, Multi-Walker, and Particle environment. We compare the results with several ablations and state-of-the-art multi-agent algorithms such as QMIX and MADDPG and also single-agent methods with shared parameters between agents such as IMPALA and APEX. The results show superior performance against other algorithms. The code is available online at https://github.com/kargarisaac/macrpo.
翻译:这项工作考虑了在多试剂环境中学习合作政策的问题,这种多试剂环境具有部分可观测和非静止环境,没有通信渠道。我们注重改进代理人之间的信息共享,并提出一个新的多试剂行为者――行为者――行为者合作的新方法,称为\ textit{Multi-Agenti Agency Company Proximization(MACRPO))(MACRPO)。我们提出了在MACRPO(MACRPO)中跨代理和时间整合信息的两个新办法:首先,我们使用批评者网络结构中的一个经常性层,并提议一个新的框架,用一个元性参数来培训经常层。这使网络能够学习代理人之间的合作和互动动态,并处理部分易用性。第二,我们提出了一个新的优势功能,将其他代理人的奖赏和价值功能结合起来。我们评估了我们在三个具有持续和离散行动空间、Deepdrive-Zero、Mul-Walker和Partic环境等具有挑战性的多剂环境的多剂环境的算法。我们比较了结果,并比较了诸如QIX和MADGPGI和A/AA的单一代理器/ADRAA的成绩。