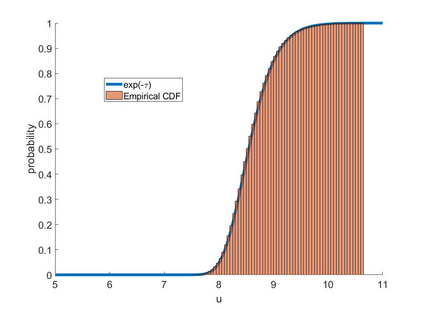
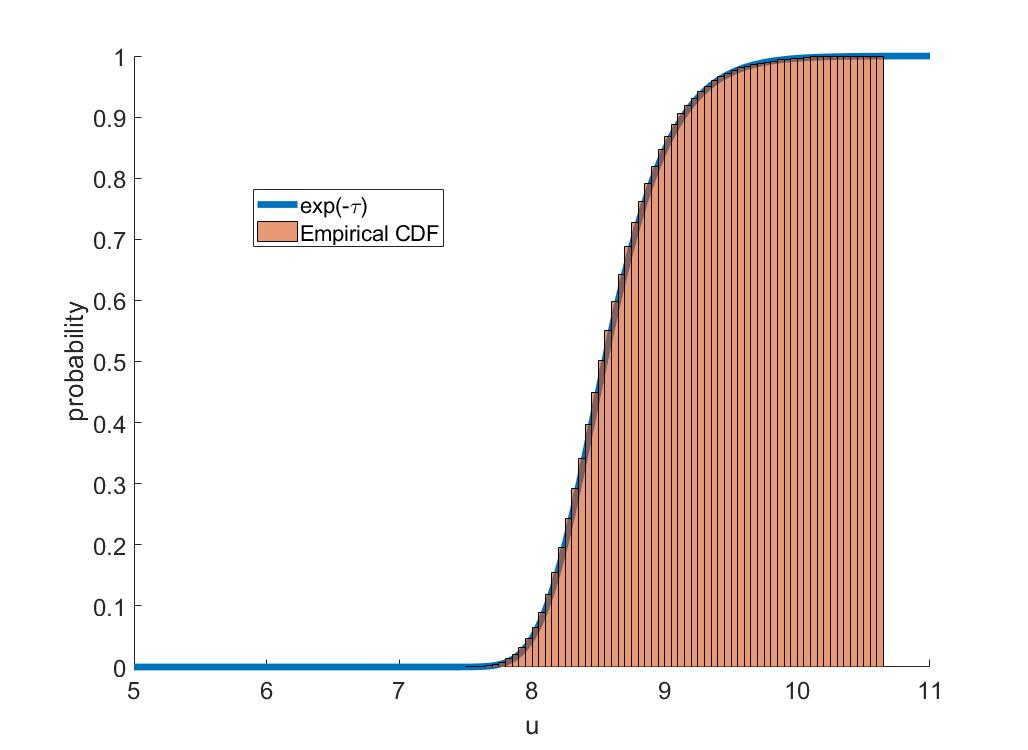
A dynamic mean field theory is developed for model based Bayesian reinforcement learning in the large state space limit. In an analogy with the statistical physics of disordered systems, the transition probabilities are interpreted as couplings, and value functions as deterministic spins, and thus the sampled transition probabilities are considered to be quenched random variables. The results reveal that, under standard assumptions, the posterior over Q-values is asymptotically independent and Gaussian across state-action pairs, for infinite horizon problems. The finite horizon case exhibits the same behaviour for all state-actions pairs at each time but has an additional correlation across time, for each state-action pair. The results also hold for policy evaluation. The Gaussian statistics can be computed from a set of coupled mean field equations derived from the Bellman equation, which we call dynamic mean field programming (DMFP). For Q-value iteration, approximate equations are obtained by appealing to extreme value theory, and closed form expressions are found in the independent and identically distributed case. The Lyapunov stability of these closed form equations is studied.
翻译:为基于模型的Bayesian加强大面积空间限制的强化学习开发了一个动态中值实地理论。在与混乱系统的统计物理类比中,过渡概率被解释为组合,而价值函数则被解释为确定性旋转,因此抽样过渡概率被视为被抑制随机变量。结果显示,根据标准假设,在州际行动对对等之间,以无限的地平线问题为基础,后端或Q值之上的后方程式是暂时独立的,高斯方程式是无限的。有限地平线案例显示所有州际行动对对对对对的每个时间都有相同的行为,但每个州际行动对对对等则有额外的关联性。结果也用于政策评价。高斯统计可以从一套由贝尔曼方程式(我们称之为动态中平均值编程(DMFP)得出的共同平均场方程式计算出来。关于Q-价值的计算,通过吸引极端价值理论获得近似方程式,在独立和相同分布的案例中发现封闭式表达方式。这些封闭式方程式的Lyapunov方程式稳定性是研究的。