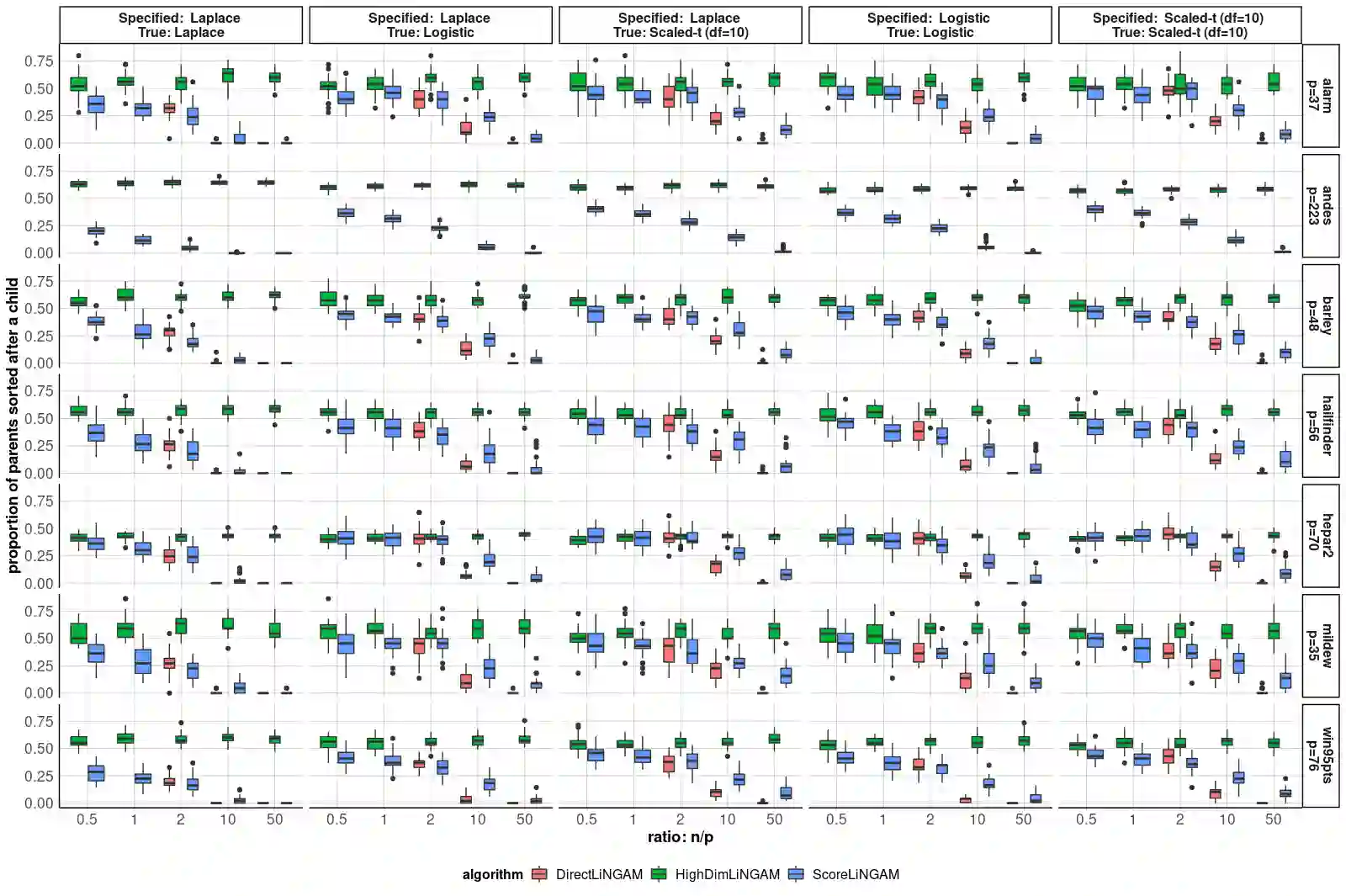
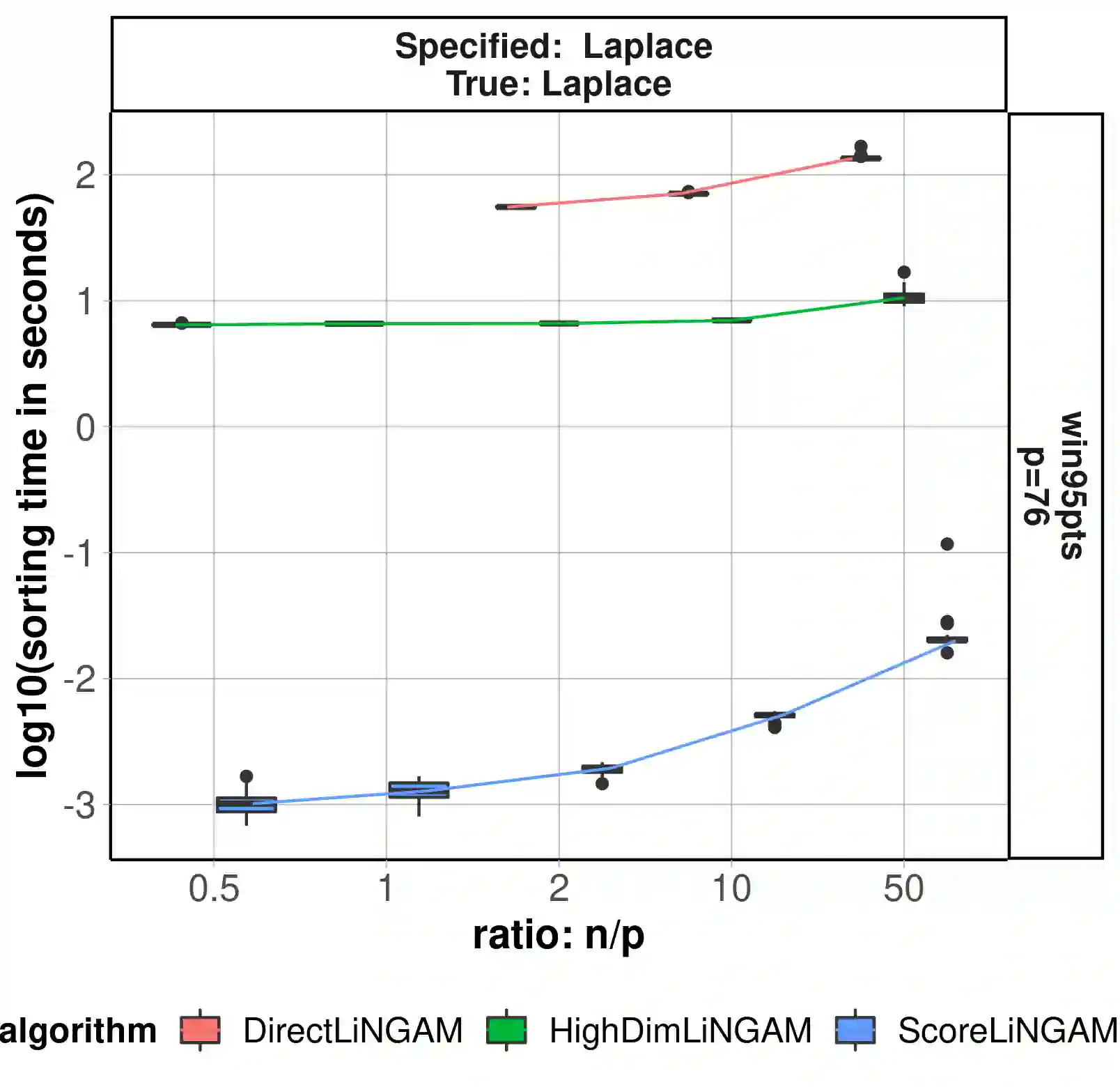
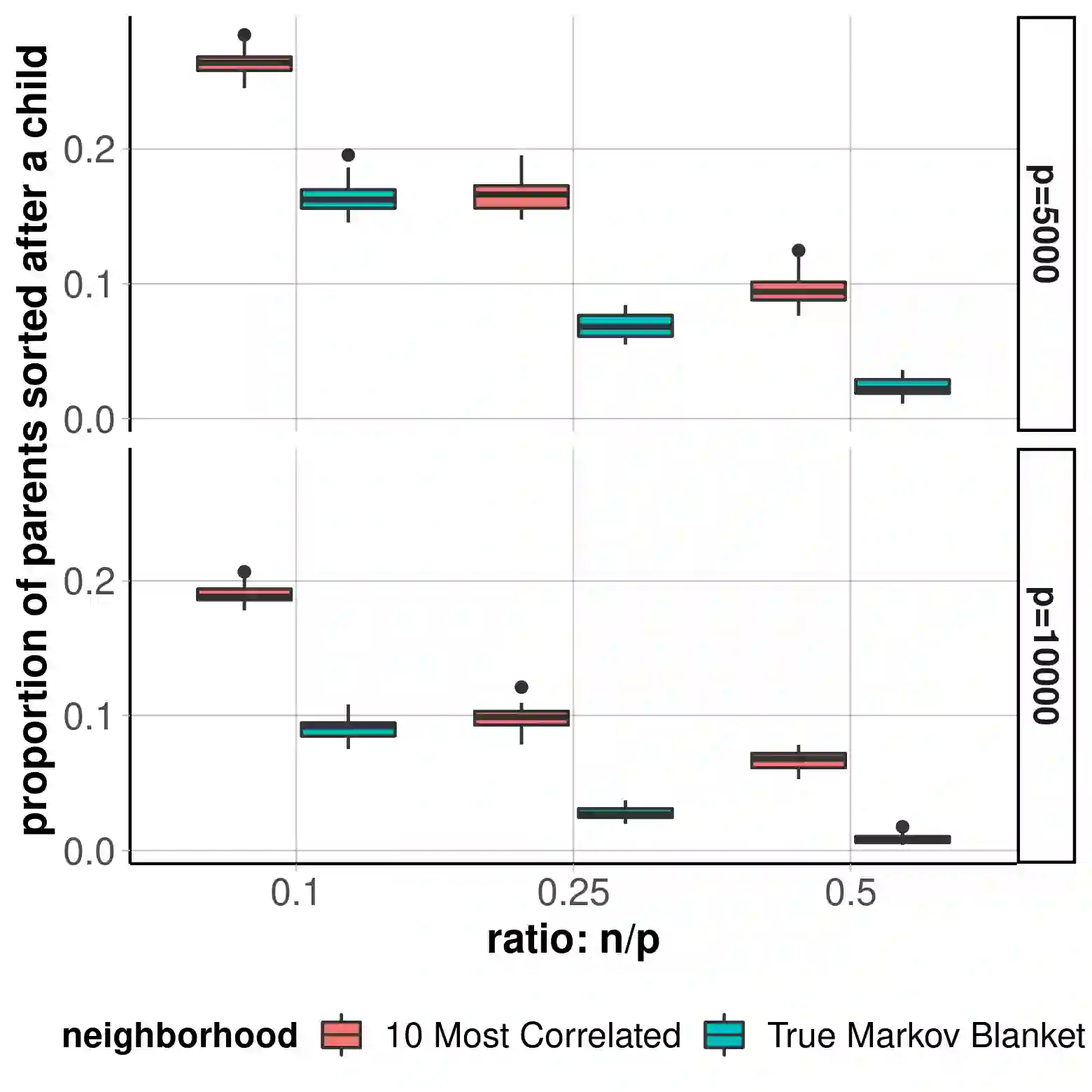
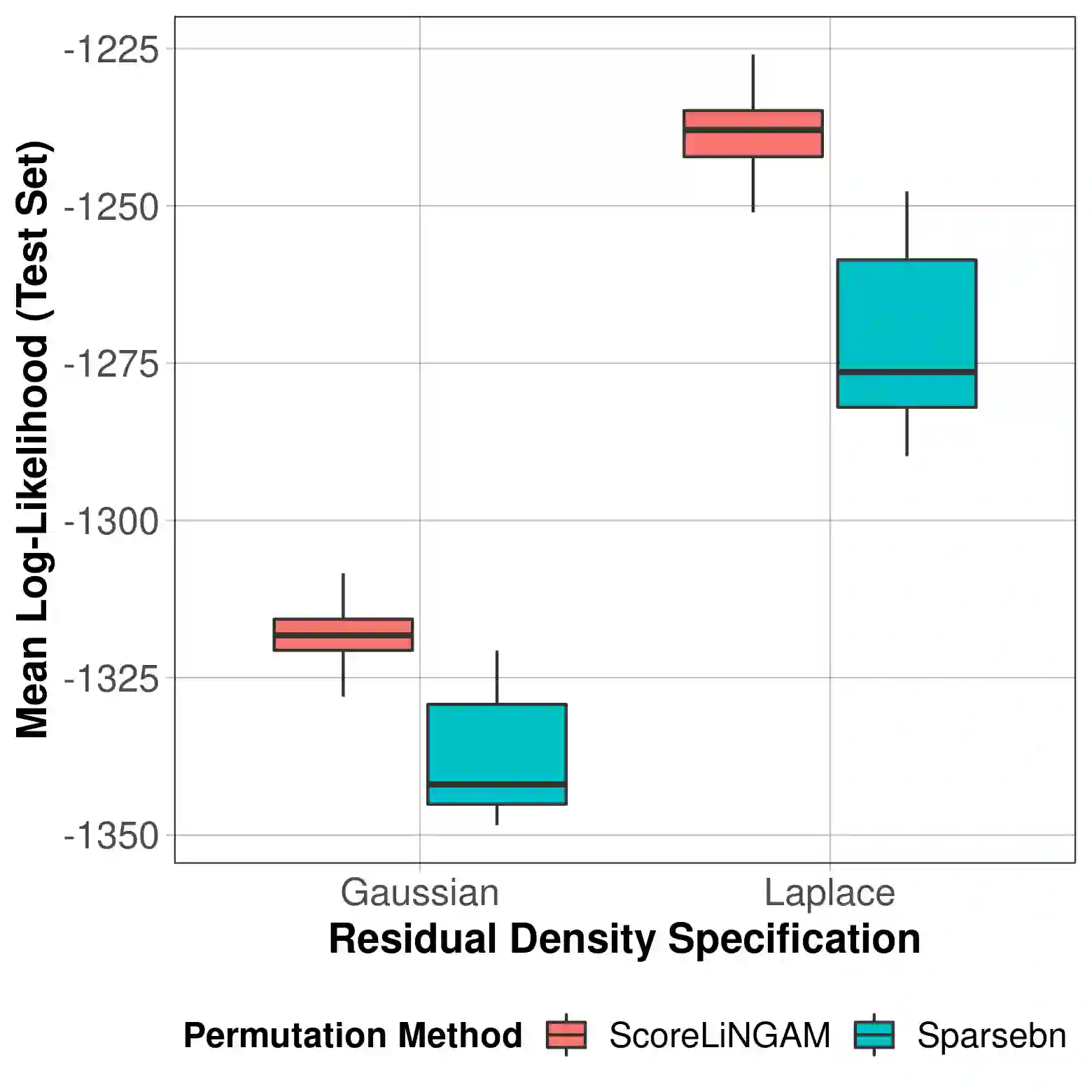
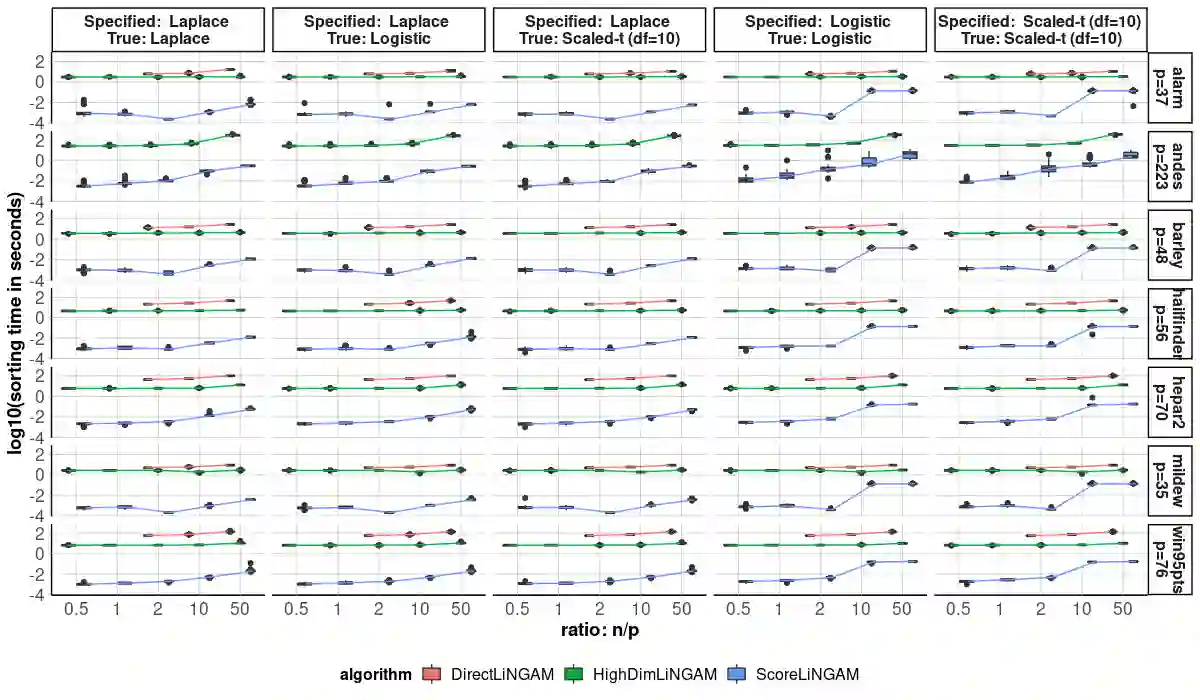
Causal discovery, the learning of causality in a data mining scenario, has been of strong scientific and theoretical interest as a starting point to identify "what causes what?" Contingent on assumptions, it is sometimes possible to identify an exact causal Directed Acyclic Graph (DAG), as opposed to a Markov equivalence class of graphs that gives ambiguity of causal directions. The focus of this paper is on one such case: a linear structural equation model with non-Gaussian noise, a model known as the Linear Non-Gaussian Acyclic Model (LiNGAM). Given a specified parametric noise model, we develop a novel sequential approach to estimate the causal ordering of a DAG. At each step of the procedure, only simple likelihood ratio scores are calculated on regression residuals to decide the next node to append to the current partial ordering. Under mild assumptions, the population version of our procedure provably identifies a true ordering of the underlying causal DAG. We provide extensive numerical evidence to demonstrate that our sequential procedure is scalable to cases with possibly thousands of nodes and works well for high-dimensional data. We also conduct an application to a single-cell gene expression dataset to demonstrate our estimation procedure.
翻译:在数据开采假设中,从科学和理论角度对因果关系的发现有了强烈的兴趣,作为确定“什么原因?”的起点,根据假设,有时有可能确定确切的因果关系直接环绕图(DAG),而不是造成因果关系方向模糊的马克夫等值类图。本文件的重点是一个此类案例:一个具有非加西语噪音的线性结构方程模型,一个称为线性非加西语环球模型(LiNGAM)的模型。根据一个特定的参数噪音模型,我们开发了一种新的顺序方法来估计DAG的因果关系。在程序的每一步,都只计算回归残留物的简单概率比率,以决定目前部分排序的下一个节点。根据比较温和的假设,我们程序的人口版可以明显地确定潜在因果关系的正确排序。我们提供了广泛的数字证据,以证明我们的顺序程序可以与可能存在数千个节点的案例相适应,并很好地用于高维度数据。我们还应用了一种单一细胞数据表达程序。