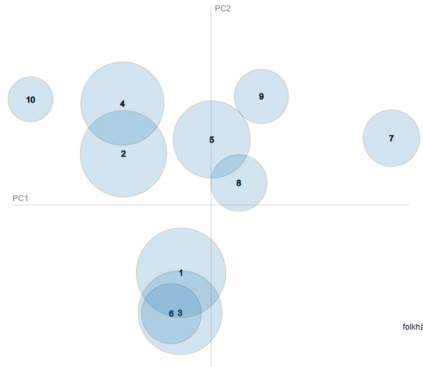
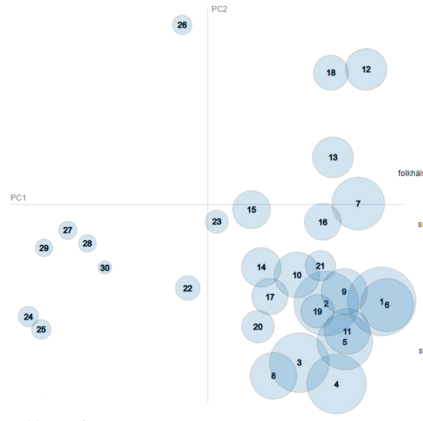
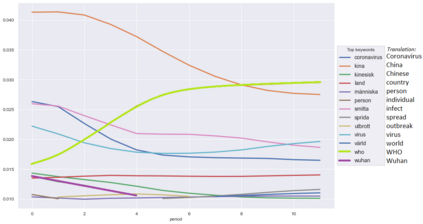
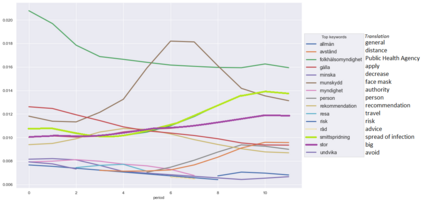
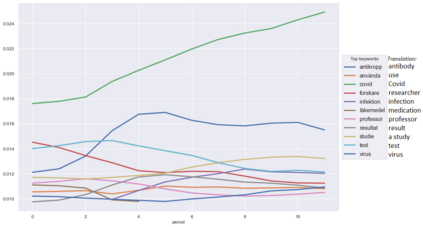
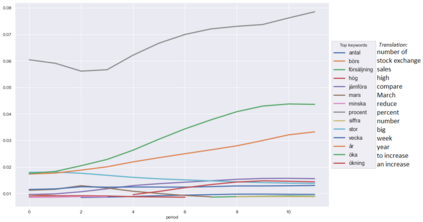
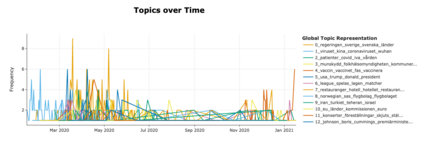
Topic Modelling (TM) is from the research branches of natural language understanding (NLU) and natural language processing (NLP) that is to facilitate insightful analysis from large documents and datasets, such as a summarisation of main topics and the topic changes. This kind of discovery is getting more popular in real-life applications due to its impact on big data analytics. In this study, from the social-media and healthcare domain, we apply popular Latent Dirichlet Allocation (LDA) methods to model the topic changes in Swedish newspaper articles about Coronavirus. We describe the corpus we created including 6515 articles, methods applied, and statistics on topic changes over approximately 1 year and two months period of time from 17th January 2020 to 13th March 2021. We hope this work can be an asset for grounding applications of topic modelling and can be inspiring for similar case studies in an era with pandemics, to support socio-economic impact research as well as clinical and healthcare analytics. Our data and source code are openly available at https://github. com/poethan/Swed_Covid_TM Keywords: Latent Dirichlet Allocation (LDA); Topic Modelling; Coronavirus; Pandemics; Natural Language Understanding; BERT-topic
翻译:话题建模(Topic Modelling,TM)来自自然语言理解(NLU)和自然语言处理(NLP)研究领域,旨在从大型文档和数据集中提供深入洞察,例如主题摘要和主题变化。在大数据分析中,这种发现变得越来越受欢迎。在本研究中,我们从社交媒体和医疗保健领域,应用流行的潜在狄利克雷分配(LDA)方法对瑞典报纸关于冠状病毒的文章进行话题建模。我们描述了我们创建的语料库,其中包括6515篇文章,应用的方法,以及关于话题变化的统计数据,跨越了从2020年1月17日到2021年3月13日约1年2个月的时间段。我们希望这项工作可以成为话题建模应用的资产,并且可以启发类似情况下的案例研究,以支持社会经济影响研究以及临床和医疗保健分析。我们的数据和源代码在https://github .com/poethan/Swed_Covid_TM公开可用。关键词:潜在狄利克雷分配(LDA);话题建模;冠状病毒;大流行病;自然语言理解;BERT-topic