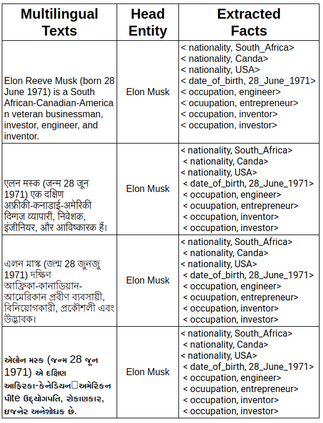
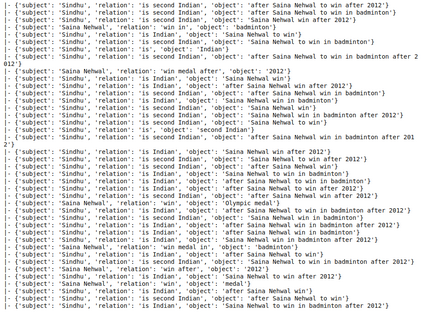
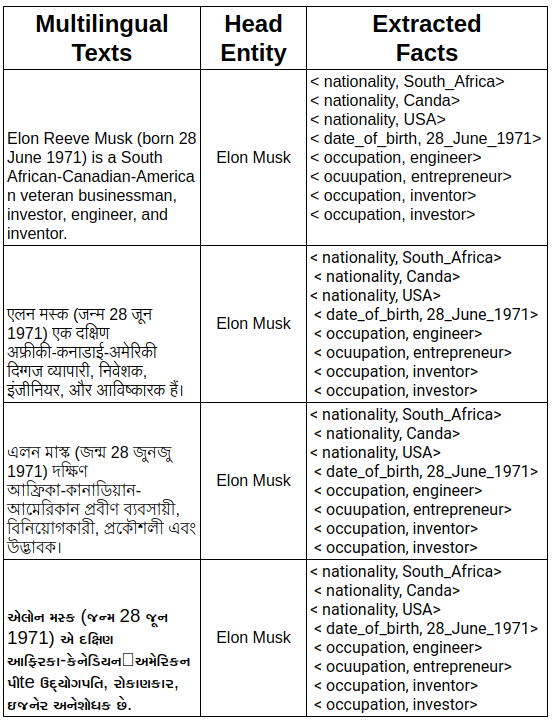
Massive knowledge graphs like Wikidata attempt to capture world knowledge about multiple entities. Recent approaches concentrate on automatically enriching these KGs from text. However a lot of information present in the form of natural text in low resource languages is often missed out. Cross Lingual Information Extraction aims at extracting factual information in the form of English triples from low resource Indian Language text. Despite its massive potential, progress made on this task is lagging when compared to Monolingual Information Extraction. In this paper, we propose the task of Cross Lingual Fact Extraction(CLFE) from text and devise an end-to-end generative approach for the same which achieves an overall F1 score of 77.46.
翻译:维基数据等大规模知识图表试图捕捉关于多个实体的世界知识。 最近的方法侧重于从文本中自动丰富这些KG。 但是,以低资源语言的自然文本形式提供的许多信息往往被遗漏。 跨语言信息提取旨在从低资源印度语言文本中以英语三重形式获取事实信息。 尽管其潜力巨大,但与单语言信息提取相比,在这项任务上取得的进展仍然滞后。 在本文中,我们提议从文本中采用跨语言事实提取(CLFE)的任务,并设计一个最终到最终的分类方法,从而达到77.46的F1总分。