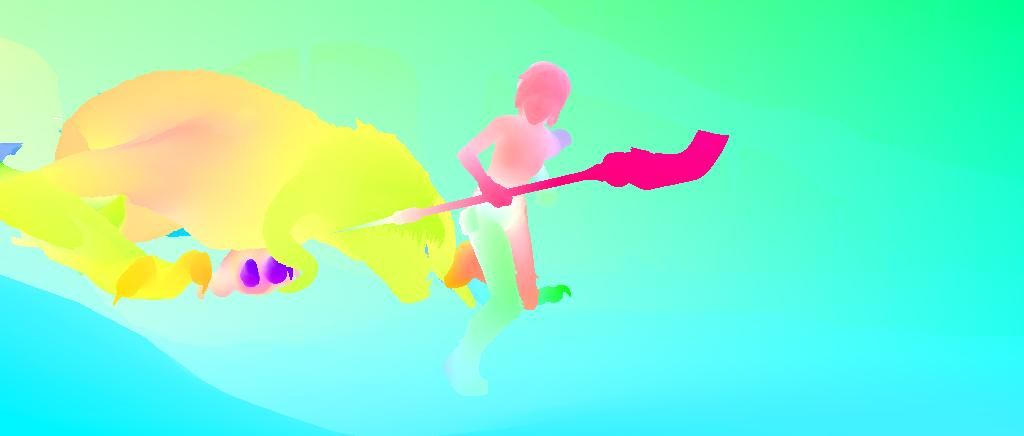The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves strong results on tasks with highly structured output spaces, such as natural language and visual understanding, StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art performance on Sintel optical flow estimation.
翻译:最近提出的 Perceiver 模型在若干领域(图像、音频、多式联运、点云)取得了良好结果,同时在计算和存储输入大小时以线性方式向线性扩展。 虽然 Perceiver 支持了多种输入, 但只能产生非常简单的输出, 如类分。 Perceiver IO 克服了这一限制, 同时又不牺牲原始的吸引力, 学会灵活查询模型的潜在空间, 以产生任意大小和语义的输出。 Perceiver IO 仍然将模型的深度从数据大小和仍然以数据大小线性尺度的模型中分离出来, 但现在在输入和输出大小方面都是如此。 完整的 Perceiver IO 模型在具有高度结构化输出空间的任务上取得了显著的成果, 如自然语言和视觉理解、 StarCraft II 以及多任务和多模式域。 作为亮点, Perceever IO 在GLUE 语言基准上与基于变压器的 BERT 基线匹配, 不需要投入表示和在Sintel光学流估计上实现最新技术表现。