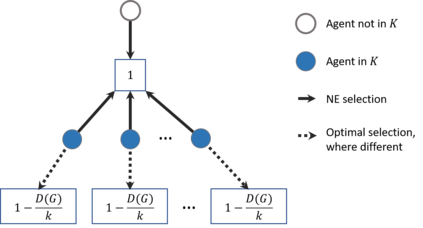
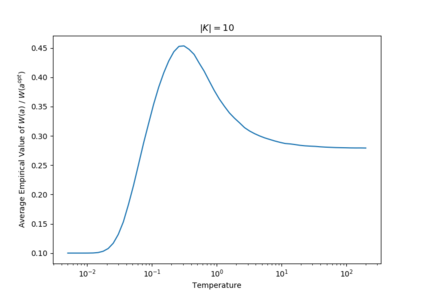
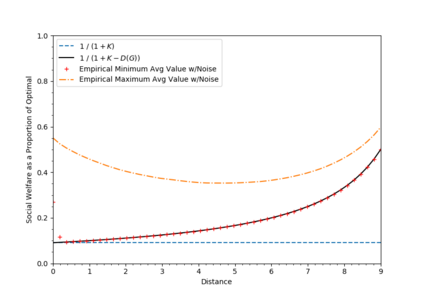
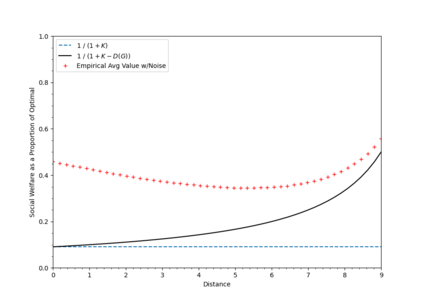
This paper considers coverage games in which a group of agents are tasked with identifying the highest-value subset of resources; in this context, game-theoretic approaches are known to yield Nash equilibria within a factor of 2 of optimal. We consider the case that some of the agents suffer a communication failure and cannot observe the actions of other agents; in this case, recent work has shown that if there are k>0 compromised agents, Nash equilibria are only guaranteed to be within a factor of k+1 of optimal. However, the present paper shows that this worst-case guarantee is fragile; in a sense which we make precise, we show that if a problem instance has a very poor worst-case guarantee, then it is necessarily very "close" to a problem instance with an optimal Nash equilibrium. Conversely, an instance that is far from one with an optimal Nash equilibrium necessarily has relatively good worst-case performance guarantees. To contextualize this fragility, we perform simulations using the log-linear learning algorithm and show that average performance on worst-case instances is considerably better even than our improved analytical guarantees. This suggests that the fragility of the price of anarchy can be exploited algorithmically to compensate for online communication failures.
翻译:本文审议了一组代理商负责确定最高价值资源子集的覆盖游戏; 在这方面,已知游戏理论方法在最佳的2个因素内产生纳什平衡。 我们考虑了一些代理商通信失败,无法观察其他代理商的行动的情况; 在本案中,最近的工作表明,如果存在 k>0 受损害的代理商,Nash equilibria 只能保证在K+1 最佳因素内。 然而,本文表明,这种最坏情况的保证是脆弱的; 从我们准确的意义上说,我们表明,如果一个问题案例有非常差的最坏的保证,那么它必然“接近”于一个具有最佳纳什平衡的问题案例。相反,一个与拥有最佳纳什平衡的代理商相比,其最坏的履约保证必然是相对良好的。要结合这种脆弱性,我们使用日志-线学习算法进行模拟,并表明最坏案例的平均表现比我们改进的分析保证要好得多。 这意味着,无政府品价格的脆弱性可以被利用,用来弥补在线通信失败。