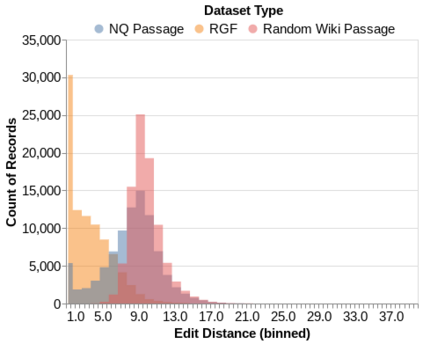
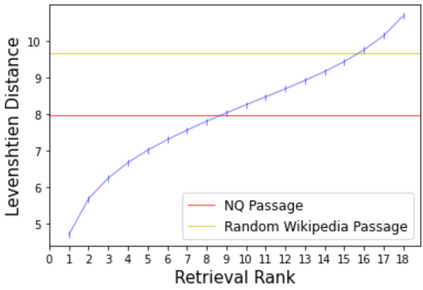
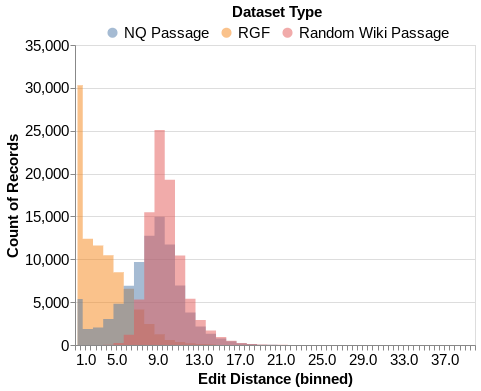
Deep NLP models have been shown to learn spurious correlations, leaving them brittle to input perturbations. Recent work has shown that counterfactual or contrastive data -- i.e. minimally perturbed inputs -- can reveal these weaknesses, and that data augmentation using counterfactuals can help ameliorate them. Proposed techniques for generating counterfactuals rely on human annotations, perturbations based on simple heuristics, and meaning representation frameworks. We focus on the task of creating counterfactuals for question answering, which presents unique challenges related to world knowledge, semantic diversity, and answerability. To address these challenges, we develop a Retrieve-Generate-Filter(RGF) technique to create counterfactual evaluation and training data with minimal human supervision. Using an open-domain QA framework and question generation model trained on original task data, we create counterfactuals that are fluent, semantically diverse, and automatically labeled. Data augmentation with RGF counterfactuals improves performance on out-of-domain and challenging evaluation sets over and above existing methods, in both the reading comprehension and open-domain QA settings. Moreover, we find that RGF data leads to significant improvements in a model's robustness to local perturbations.
翻译:深度 NLP 模型被证明学习了虚假的关联性,让它们容易被输入扭曲。最近的工作显示,反事实或对比性数据 -- -- 即最少受扰动的投入 -- -- 能够揭示这些弱点,使用反事实增强数据有助于改善这些弱点。 生成反事实的拟议技术依赖于人类的注释、基于简单超自然学的扰动和代表框架。我们侧重于为回答问题创建反事实的任务,这提出了与世界知识、语义多样性和可回答性有关的独特挑战。为了应对这些挑战,我们开发了一种反事实或对比性数据 -- -- 即最小受扰动的投入 -- -- 能够揭示出这些弱点,而使用反事实性数据增强数据,使用以原始任务数据培训的开放式 QA 框架和问题生成模型,我们创建了流性、语义多样性和自动标注的反事实。 数据增强与RGF反事实,提高了外部和具有挑战性的评价模型的性能。为了应对这些挑战,我们开发了一种反事实性评价技术,在最低限度的人类监督下创建反事实性评价数据,从而在现有的方法中找到重要的直观和直观。