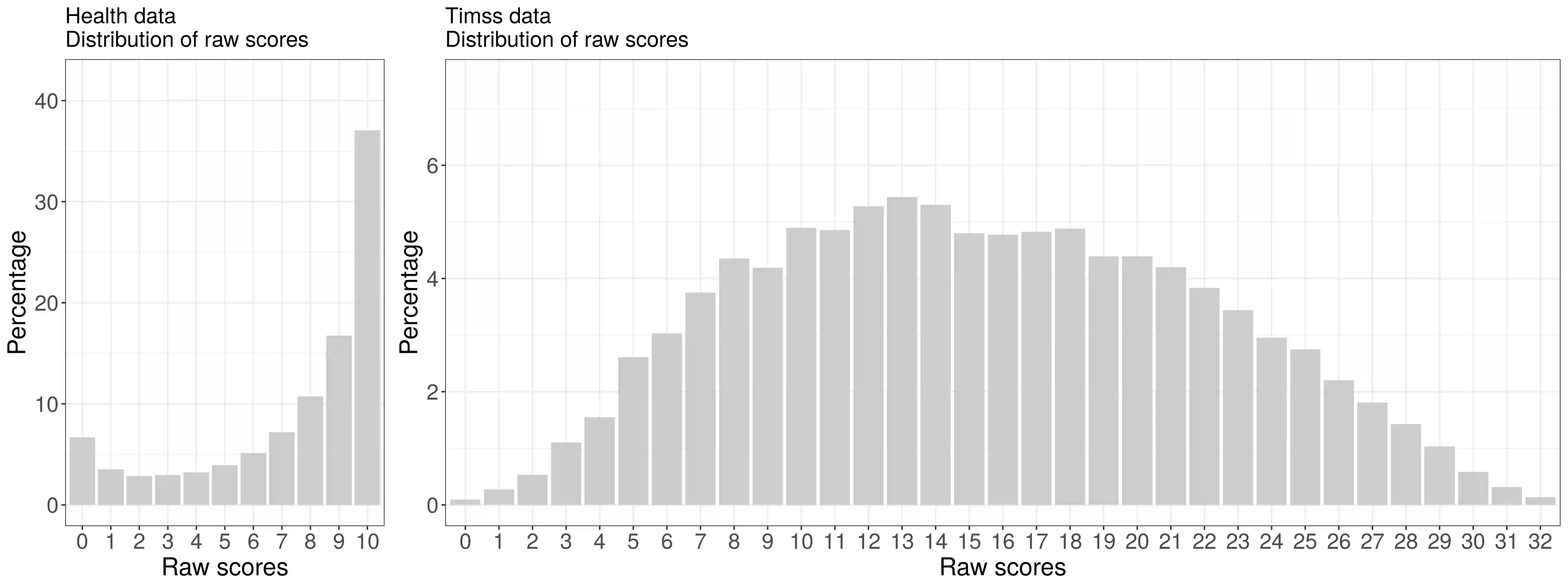
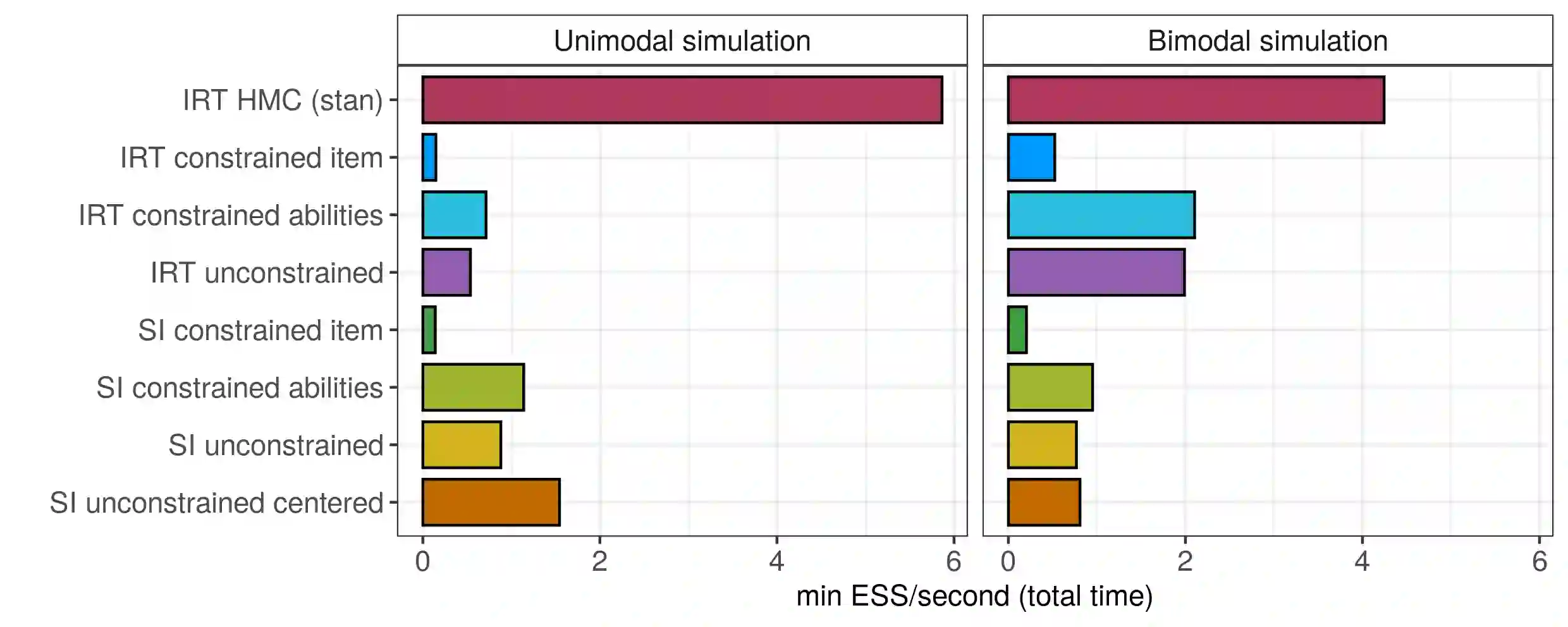
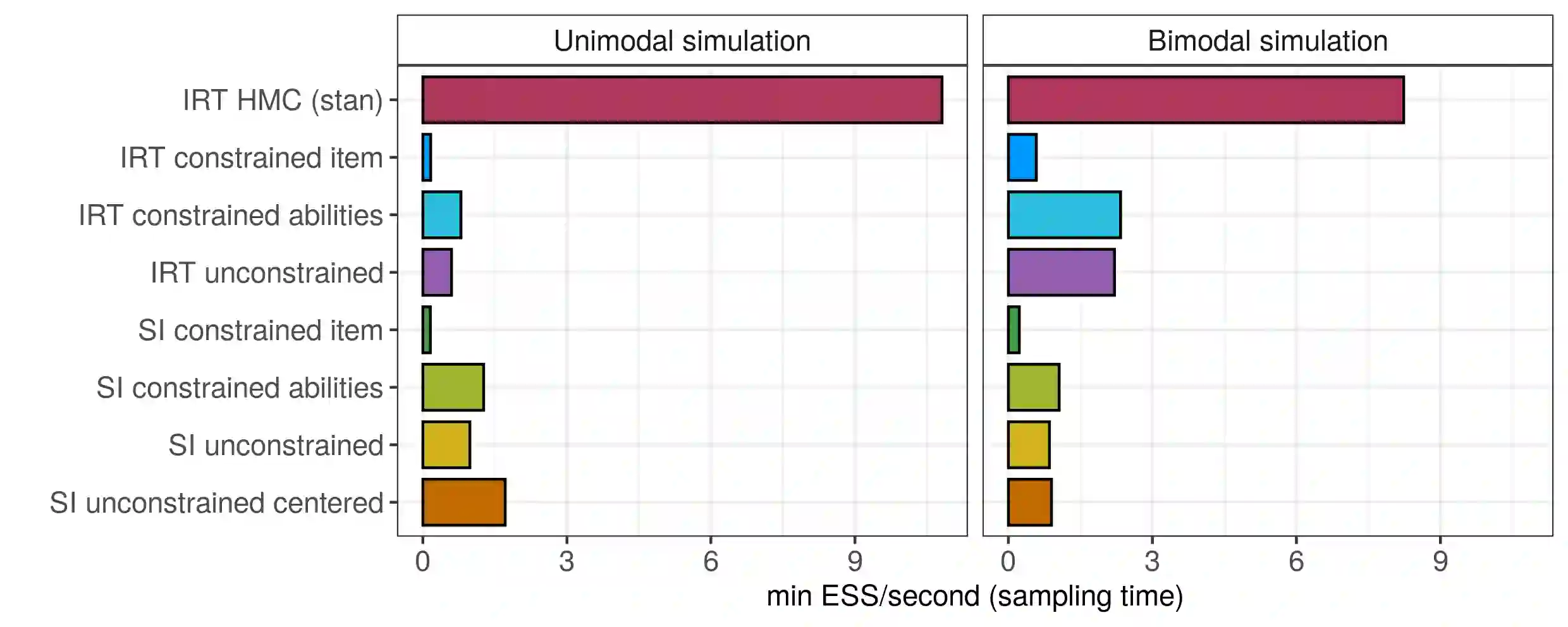
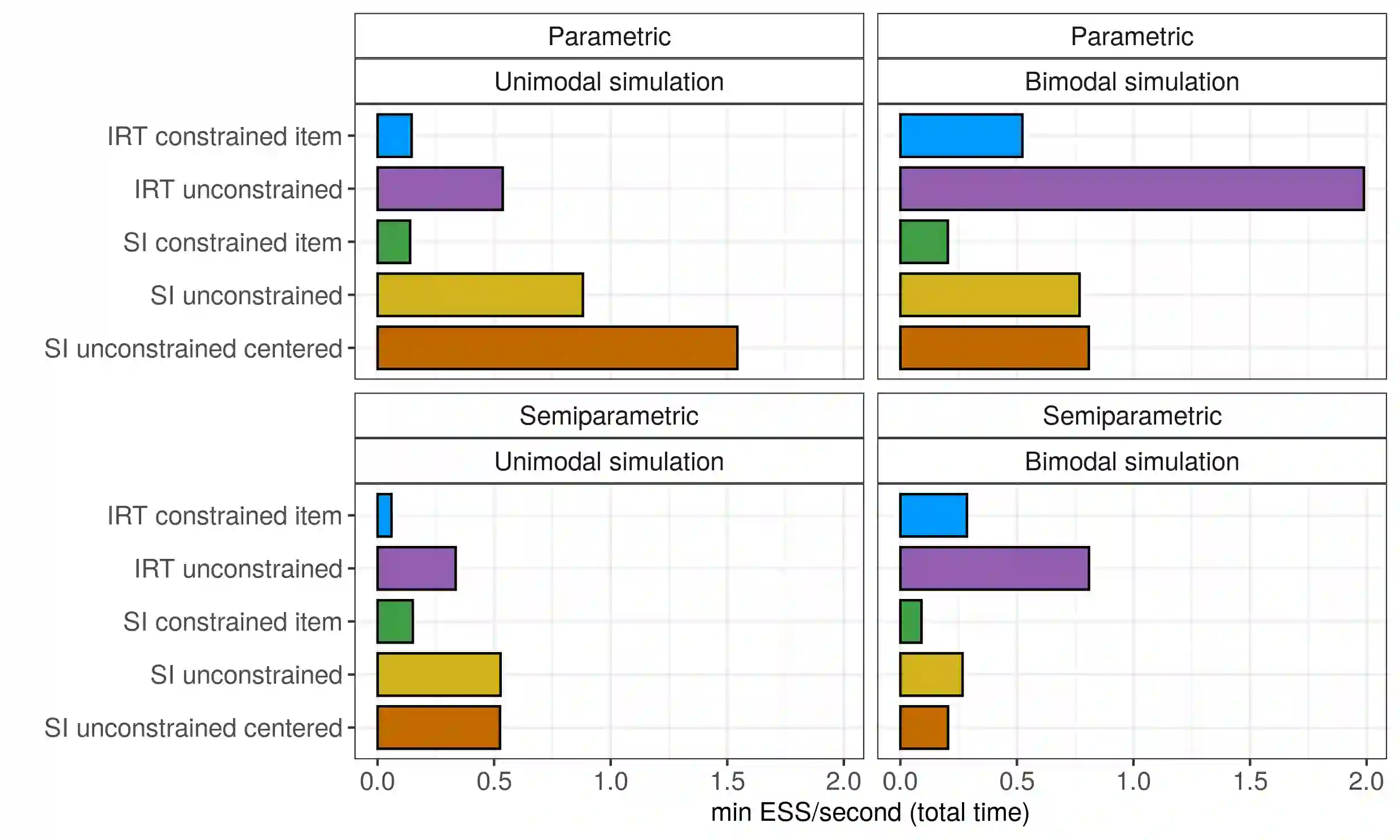
Item response theory (IRT) models are widely used to obtain interpretable inference when analyzing data from questionnaires, scaling binary responses into continuous constructs. Typically, these models rely on a normality assumption for the latent trait characterizing individuals in the population under study. However, this assumption can be unrealistic and lead to biased results. We relax the normality assumption by considering a flexible Dirichlet Process mixture model as a nonparametric prior on the distribution of the individual latent traits. Although this approach has been considered in the literature before, there is a lack of comprehensive studies of such models or general software tools. To fill this gap, we show how the NIMBLE framework for hierarchical statistical modeling enables the use of flexible priors on the latent trait distribution, specifically illustrating the use of Dirichlet Process mixtures in two-parameter logistic (2PL) IRT models. We study how different sets of constraints can lead to model identifiability and give guidance on eliciting prior distributions. Using both simulated and real-world data, we conduct an in-depth study of Markov chain Monte Carlo posterior sampling efficiency for several sampling strategies. We conclude that having access to semiparametric models can be broadly useful, as it allows inference on the entire underlying ability distribution and its functionals, with NIMBLE being a flexible framework for estimation of such models.
翻译:在分析问卷数据时,广泛使用项目反应理论(IRT)模型来获取可解释的推断,将二进制反应缩小到连续结构中。通常,这些模型依赖对所研究人群中个人潜在特征特征的常态假设,但这一假设不现实,可能导致有偏差的结果。我们放松正常性假设,将灵活的迪里赫莱特进程混合物模型视为在分配个别潜在特征之前的非参数。虽然以前在文献中曾考虑过这一方法,但对此类模型或一般软件工具缺乏全面研究。为填补这一空白,我们展示了等级统计模型的NNNNBLB框架如何能够在潜在特征分布上使用灵活的前科,具体地说明Drichlet进程混合物在双参数后勤(2PL)IRT模型中的使用情况。我们研究不同的制约因素如何导致模型的可识别性,并就先前的分布提供指导。我们利用模拟和现实世界数据,对Markov链 Monte Car Festior 取样效率进行深入的研究。为若干取样战略提供了一种实用性的能力。我们得出结论认为,功能性框架的利用这种半参数框架可以作为基础,从而推估测测测测。