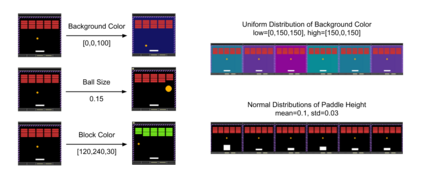
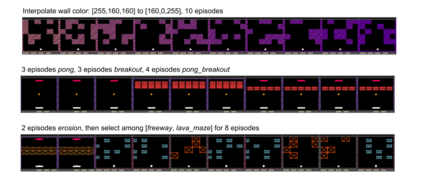
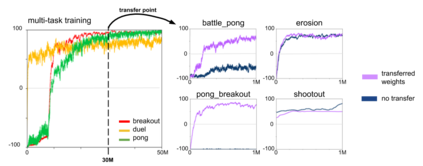
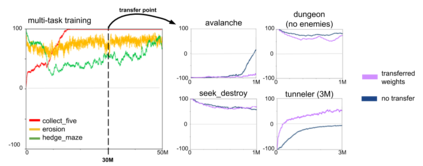
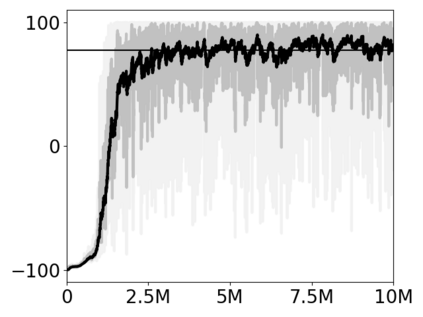
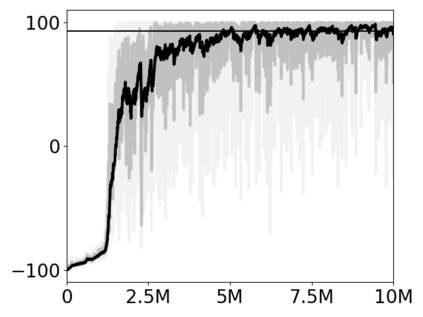
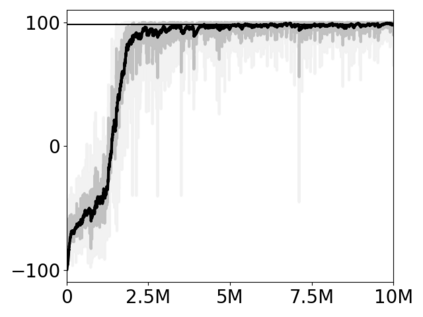
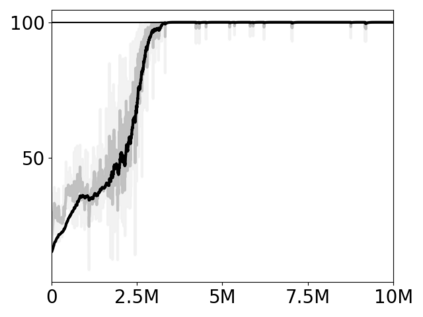
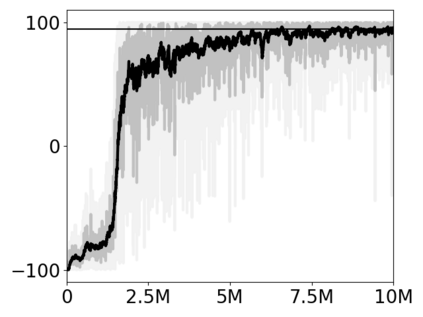
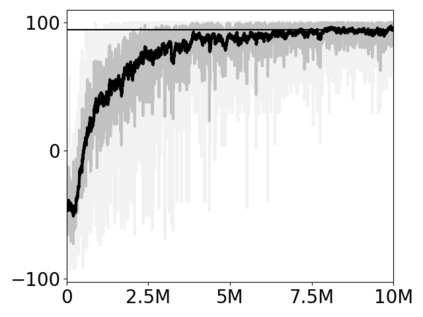
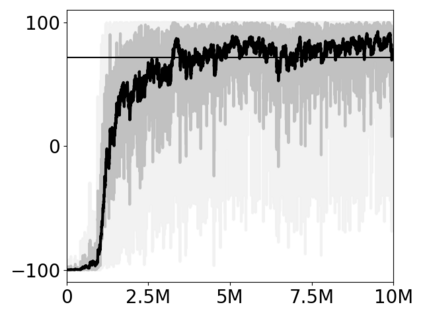
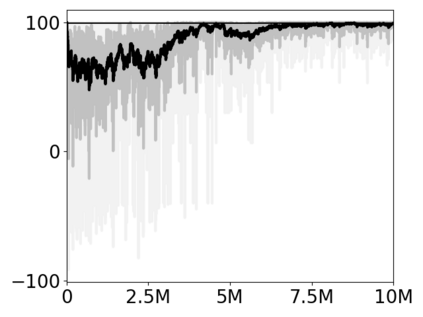
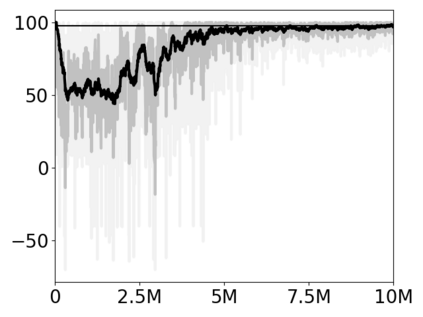
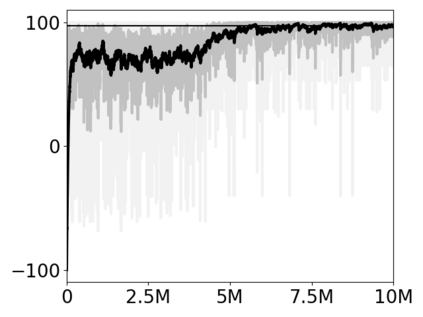
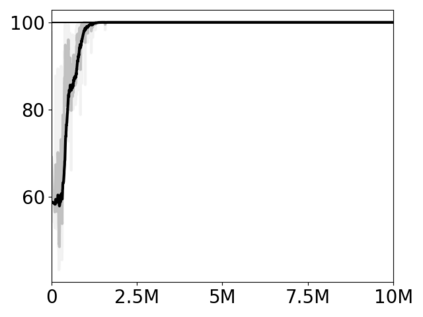
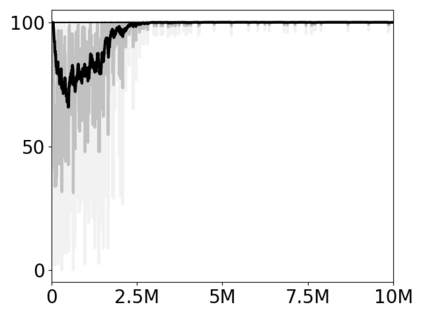
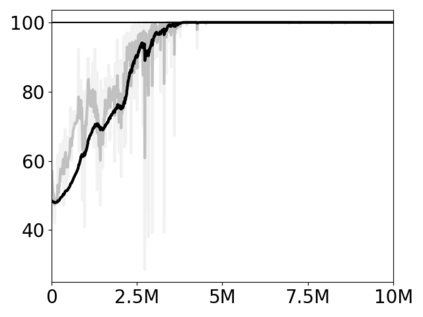
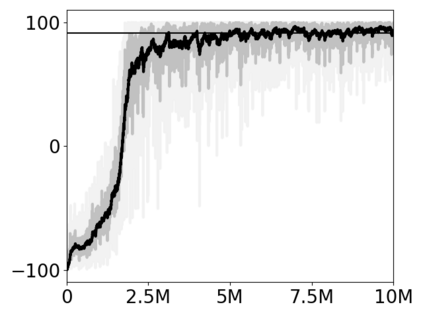
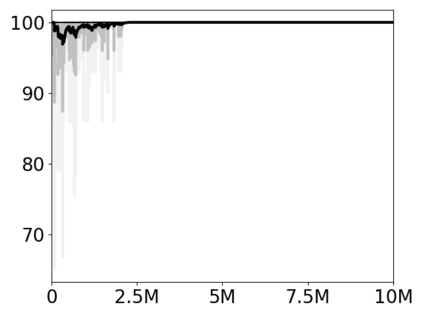
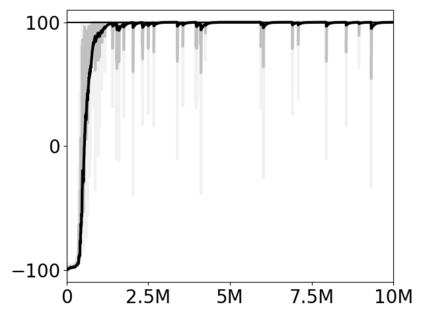
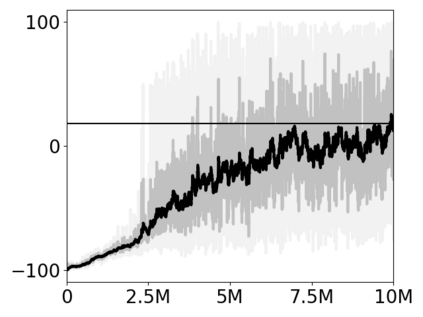
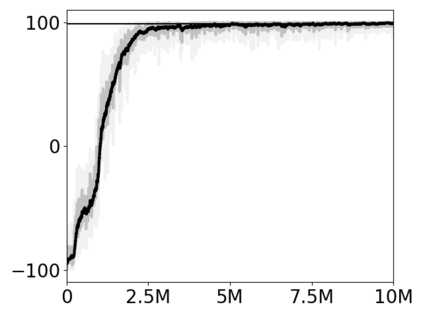
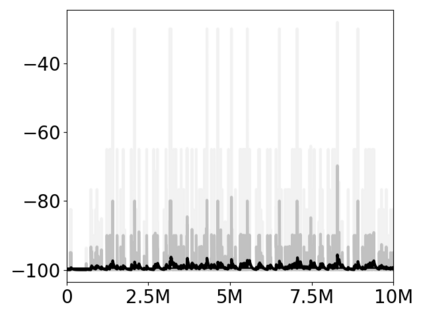
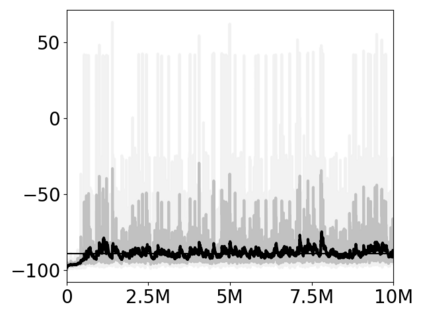
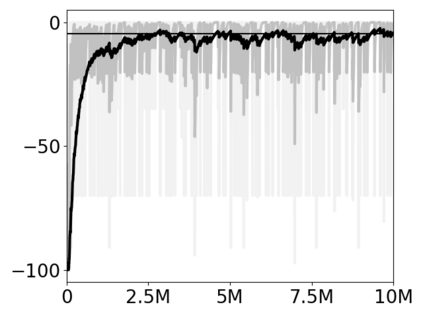
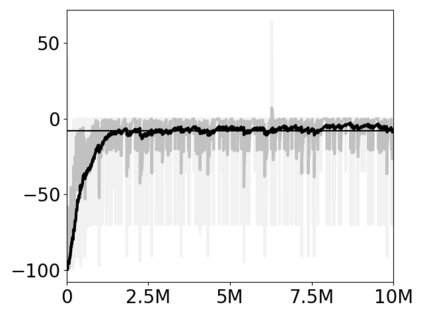
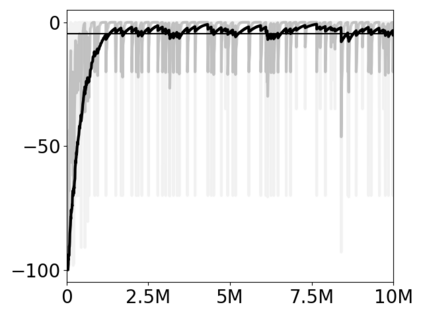
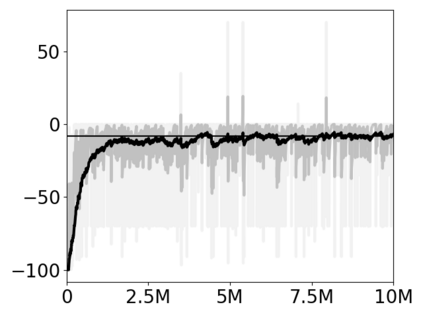
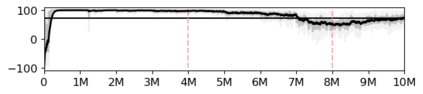
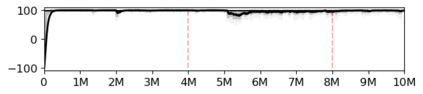
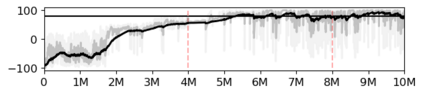
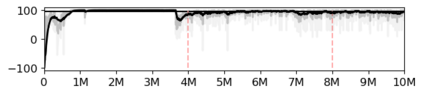
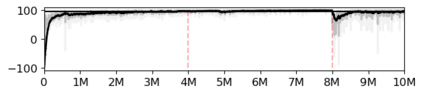
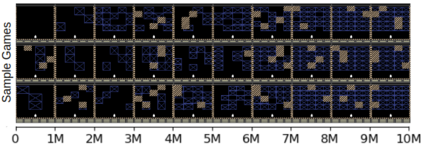
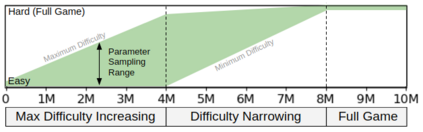
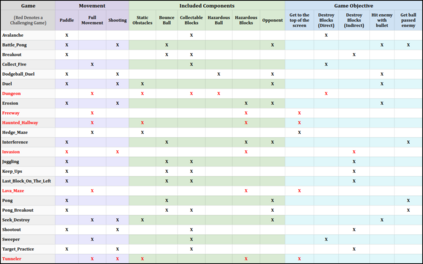
Most approaches to deep reinforcement learning (DRL) attempt to solve a single task at a time. As a result, most existing research benchmarks consist of individual games or suites of games that have common interfaces but little overlap in their perceptual features, objectives, or reward structures. To facilitate research into knowledge transfer among trained agents (e.g. via multi-task and meta-learning), more environment suites that provide configurable tasks with enough commonality to be studied collectively are needed. In this paper we present Meta Arcade, a tool to easily define and configure custom 2D arcade games that share common visuals, state spaces, action spaces, game components, and scoring mechanisms. Meta Arcade differs from prior environments in that both task commonality and configurability are prioritized: entire sets of games can be constructed from common elements, and these elements are adjustable through exposed parameters. We include a suite of 24 predefined games that collectively illustrate the possibilities of this framework and discuss how these games can be configured for research applications. We provide several experiments that illustrate how Meta Arcade could be used, including single-task benchmarks of predefined games, sample curriculum-based approaches that change game parameters over a set schedule, and an exploration of transfer learning between games.
翻译:深度强化学习(DRL)的多数方法都试图一次解决一项单一任务。因此,大多数现有研究基准包括单个游戏或游戏套件,这些游戏具有共同的界面,但其感官特征、目标或奖赏结构很少重叠。为了便利研究受过训练的代理人之间的知识转让(例如通过多任务和元学习),需要有更多的环境套件,提供足够共性可集体研究的可配置任务。在本文中,我们介绍了Meta Arcade,这是一个易于定义和配置自定义的 2D 街机游戏的工具,这些游戏有共同的视觉、州空间、动作空间、游戏组件和评分机制。Meta Arcade与先前的环境不同,前者优先考虑的是任务共性和可配置性:整套游戏可以根据共同要素构建,这些要素可以通过暴露参数进行调整。我们包括一套24个预先定义的游戏套件,共同说明这一框架的可能性,并讨论如何将这些游戏配置为研究应用。我们提供了几种实验,说明如何使用Meta Arcade,包括预先定义的游戏、试样游戏的游戏时间表、游戏法和游戏的改变。